This post is a mirror of a tweet I made on why I expect inequality to increase as AI progresses.
ai is a force of extreme empowerment. currently it seems like many AI tools will be broadly available for anyone to use. many people refer to this as the ‘democratization’ of technology.
however! the outcomes that occur when you give everyone access to something are nowhere near equitable. much of the US has access to gyms and everyone to the outdoors, yet not only is health and strength not attained by all, but it’s very clear that there are long tails in these distributions, and that small sections of the population are several times stronger than average as a result.
this phenomenon repeats itself almost everywhere you look. alcohol is available for any adult to drink regardless of whether you have a genetic history of alcoholism or your religion prohibits you from trying it. megapacks of oreos are available to us all even if we have sworn off of sugar and even if our maladjusted gut microbiomes provide such strong signals to consume them that we literally cannot hold ourselves back.
chatgpt truly does offer improvement to millions of people, but I already see a select few thousand that are using it to make themselves 6-7 figures a year worth in productivity increases, which is likely >100 times the median outcome. the tails of these outcomes, the post-pmf startups with ten cracked engineers in an SF basement using LLMs as a fish uses water, takes this even further.
you don’t have to be singularitypilled to see that AI is likely to significantly increase inequality – and certainly not just that of wealth, but of ability as well. although this is one of the reasons proponents of foss AI commonly cite to further their cause, they generally do a poor job at modelling the real world outside of other programmers. foss ai is likely to help the startups keep up with the incumbents, but it is not going to help normal people keep up with the world of technology which has already outpaced them so thoroughly.
further strengthening this effect, we often use this drastic increase in our productivity to create products which then decrease the ability of others. youtube shorts and tiktok are great examples of this, where the tail-end of successful and capable individuals in society spend their high amounts of agency and intelligence on crafting products explicitly designed to keep the other less fortunate cohorts of society drooling at their screens for hours a day.
it certainly rings true to me that it’s much easier to raise the ceiling than the floor, and that is generally why technology is developed the way it is – simply because there are not other paths societies can reasonably coordinate upon for eventually making things available to everyone.
but the real world is and has always been dominated by power-law distributions, and escaping them is not an easy task. even if you have ai. especially if you have ai.
this isn’t necessarily a doomer take – it is possible to have worlds with large inequities which nonetheless are still beautiful, thriving, and have constantly decreasing amounts of suffering over time. i won’t pretend to predict which timeline we have ended up in ourselves, but i would certainly be long anything from ‘chaos’ to ‘inequality of agency’ if i could.
i’d like to have also included that wealth isn’t fixed – so an inequality in wealth does not mean others are less wealthy in absolute terms, as it’s easy to create more. this is the primary mechanism by which our society has improved and i think the floor will continue to raise.
Kalshi is an up-and-coming legal US prediction market regulated by the CFTC.
The markets on Kalshi each have a betting limit which may be found within a PDF sent to the CFTC by KalshiEX LLC.
Unfortunately these PDFs are formatted differently (some even have the limit as an image rather than text). To make discovering betting limits even more tedious, there’s 702 of these PDFs (all linked on this page). As the second-highest user on the Kalshi leaderboard (of course there’s a leaderboard…) I needed to know all of these limits.
I used Claude‘s PDF beta API to extract all information from the PDFs and include it here. All coding work took me a total of fifteen minutes from scraping->extraction->summarization->this blog post.
You can sort and search the below list if for any reason you need to know the per-market contract limits on Kalshi. Most markets have a limit of $25K USD, although some larger markets have limits of $7M or $50M. Hopefully the CFTC allows these to be increased in the future! If you enjoyed this post you may also like my personal finance tips post.
After much reading and discussions of post-TAI (transformative AI) futures from those leading the AGI labs and startups of SF, there’s a few consistent disagreements I find myself having.
While I generally agree with narrow-yet-strong capability predictions, for example that AI will enable the creation of new software, pharmaceuticals, and companies at much greater speeds, I consistently disagree with the social and cultural predictions I see from my peers.
Humanity is often treated as a constant in such predictions, with technology as the mutating variable. This leads to wildly miscalibrated predictions about the future.
This post muses on this topic a bit. It contains four sections:
I. Culture is downstream of technology
II. Time spent consuming digital content (technology) is increasing
III. Successful digital content decoheres from reality
IV. As a result, people and culture will decohere from reality
I. Culture is downstream of technology
When discussing long-term futures (post-AGI/ASI) it’s common for technologies like genetic engineering and neural interfaces to be brought up, as most serious thinkers realize it is simply not possible for humanity to persist as-is. Competitive forces will destroy those who are not augmented with technology. While this may sound stark, it has been the status quo for thousands of years – the primary difference this time is it will happen more quickly. If I refused to use the Internet, cell phones, or even basic tools, our present society would severely punish me both economically and socially. I’d have trouble holding a job, maintaining friendships, or even finding food and shelter.
I don’t intend to opine about what will happen with BCI or gametogensis or embryo selection or anything of the sort here; rather my point is about the shorter-term: the things that will happen even if the hardware humanity runs on remains a constant.
Phrased as succinctly as possible: culture is downstream of technology.
Culture is an emergent phenomenon induced by the personalities of people; if it’s the case that personalities are downstream of technology, then it follows that culture will be as well. When thinking about uses of future technology one should not think “what would the people of today do if given this?” but rather “what will the people of the future, after everything from the present to the future first modifies them, afterwards do if given this?”. When electricity was invented no one was making forecasts of how much of it would be spent mining bitcoin or powering ad recommendation systems or training large language models, yet these are currently among the most transformative use cases society is employing.
We can go a step further than this too, because future technology is built by future people, not by present people. The things people will want to build later this century are likely not things we think we want now, because those in the future will have different values and cultures (even if our substrate/hardware remains constant, which I also believe won’t be the case).
Societies used to consist of mere hundreds but now consist of millions in part due to the agricultural revolution, the effects of which are hard to overstate, allowing for hierarchical societies, specialized labor, and organized religion. The printing press caused book prices to fall by 98% within decades, helping to consolidate language and improve literacy. The effects of simple single inventions like the steam engine, the mechanical clock, or birth control have all caused massive first-order effects and even more massive second-order effects.
All of the cultural changes which seem most important have all been caused by technology when properly examined. Some obvious examples include city-states (influenced by agriculture), the abolition of slavery (influenced by industrialization, transportation, communication), extension of the franchise to both sexes (influenced by birth control, household labor-saving devices from washing machines to vacuum cleaners to refrigerators and more), universal education (influenced by mass printing), and mutually-assured destruction (required nuclear weapons in our most recent instance).
While it’s true that many basic human values have remained constant, the methods we employ to satisfy them have drastically changed as technology has modified our environments and our cultures. When I first learned about the Internet while young I imagined how amazing it would be to be able to speak with literally anyone anywhere in the world, and how that could enable optimized match-making of every type (friendships, employment, relationships, etc). I’m happy to now conclude that it is in fact, very amazing! Yet I didn’t predict that loneliness would drastically increase among younger and more online groups. If I had done a much better job forecasting incentive structures perhaps I could have made this prediction, but it’s often unintuitive, intellectually unpopular, and further confounded by how unpredictable much of our most important events and inventions end up being (as a side note I still find it frustrating that we lost proper Internet dating with OKC and it has not been brought back even a decade later. The market is a cruel force!).
If you get anything out of this section I’d like it to be that projecting your current desires onto future-humanity’s-desires may not be as straightforward as you think. I often hear people tell me they can’t wait for humanity to explore the stars, but the humanity of 100 or even 20 years from now may have very different goals.
For this reason I find most “post-AGI futures” I read about woefully incoherent, with the most common mistake being the author projecting their own values onto the future rather than attempting to simulate that-which-decides-the-values-of-future-people and make projections from the results. Although there’s many points I disagree with about the standard methodologies of thoughts here, for the purpose of this post I’m only going to focus on a sub-point, which is that the lived experiences of future humans will have almost nothing to do with base reality.
I’d like to add to the above take: reality is already on its way out (and in some cases has been fully decimated) for millions of people.
Sometimes I hear someone in SF say something like “What if people spend hours a day talking to AIs rather than humans? Isn’t that concerning, like they’d be living in a fantasy world?” (for those of you reading from Home, yes, people are actually this out of touch here). I love my friends here, but most of them have a six/seven-figure job they love and more real-life friends than they know what to do with. It’s difficult for them to know what life is like for the average American zoomer as a result.
Anyway, time for some charts.
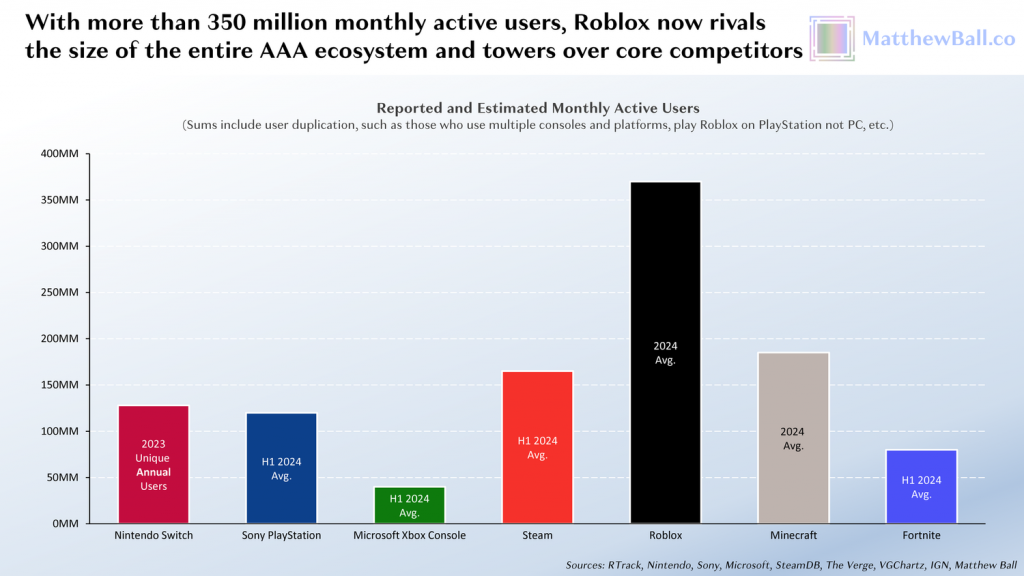
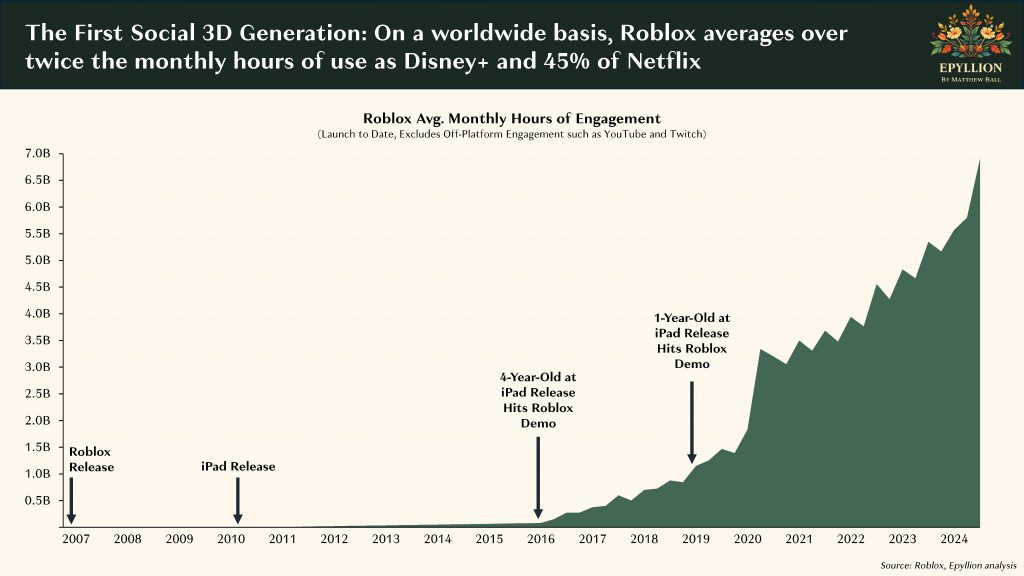
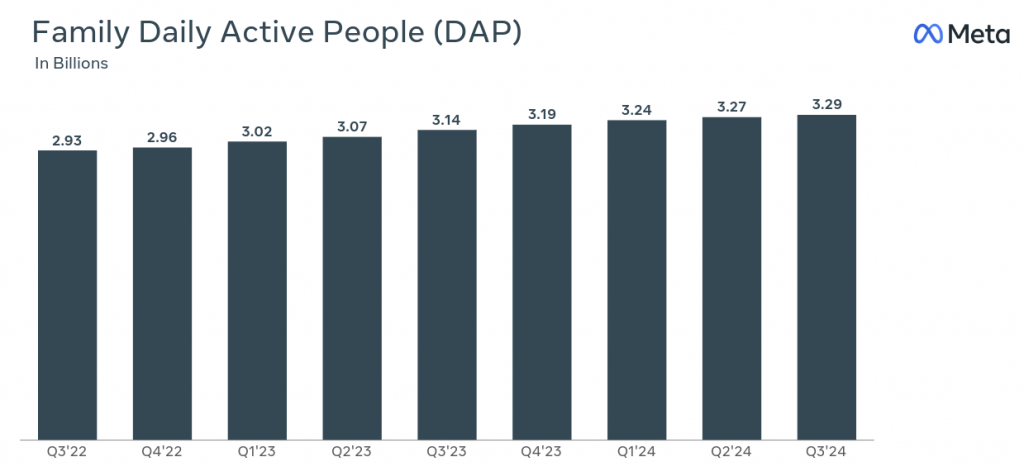
First: Roblox has more monthly active users than the entire population of the United States
Fifth: Meta’s daily userbase seems to be growing more slowly. Perhaps this is because over half of Earth’s population with Internet access are already daily users (3.29B / ~5.52B -> 60%).
While I can’t share up-to-date Character AI numbers, I can share what was posted in their series A blog post from the before-times, all the way back in March 2023 (since that date, there are now many companies with equal or greater numbers. most kids will end up not interacting with other humans much at all if we extrapolate out 5-10 years):
American zoomers spend around seven hours on their phones each day, and there’s many cohorts of desktop users and console gamers (generally males) who average 5-8+ hours a day. I myself averaged 14 hours a day for several years in a row when I was younger.
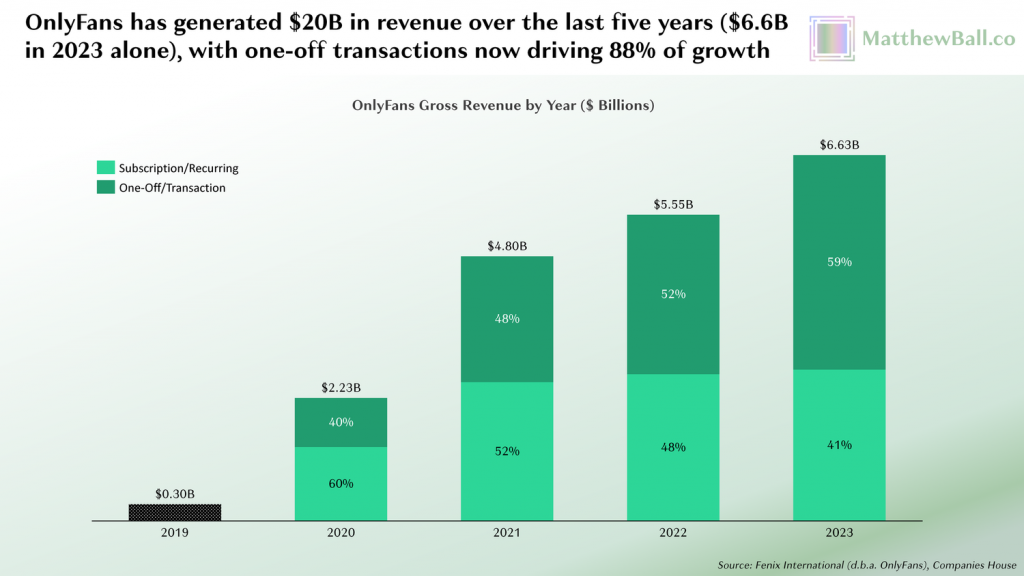
There’s 50 additional charts I’d love to include here (especially more charts with mobile games and social media), but the point is already lucid: much of humanity’s time is already spent inside virtual worlds. The proportion is rapidly increasing, especially among younger demographics.
III. Successful consumer content decoheres from reality
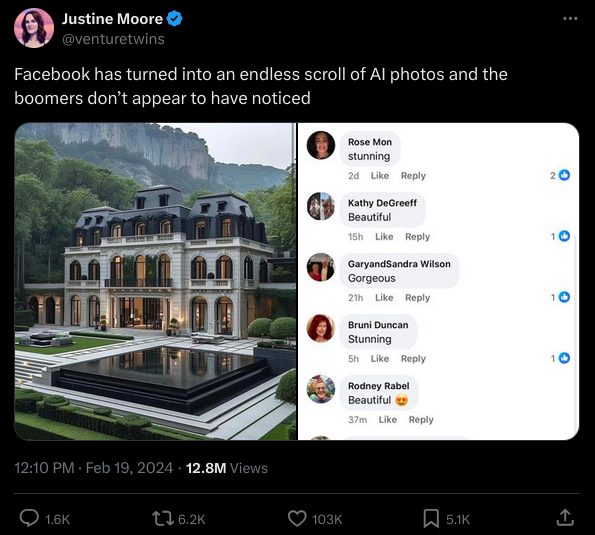
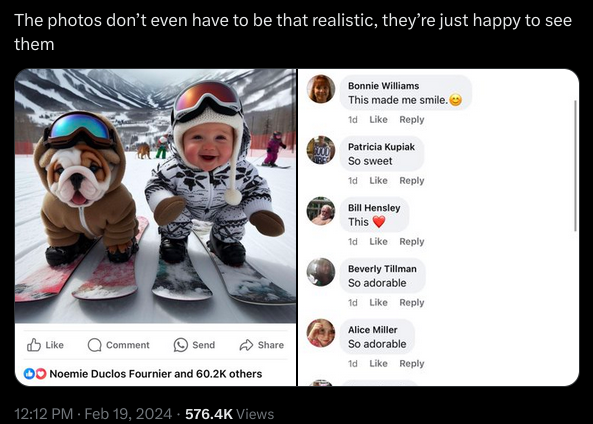
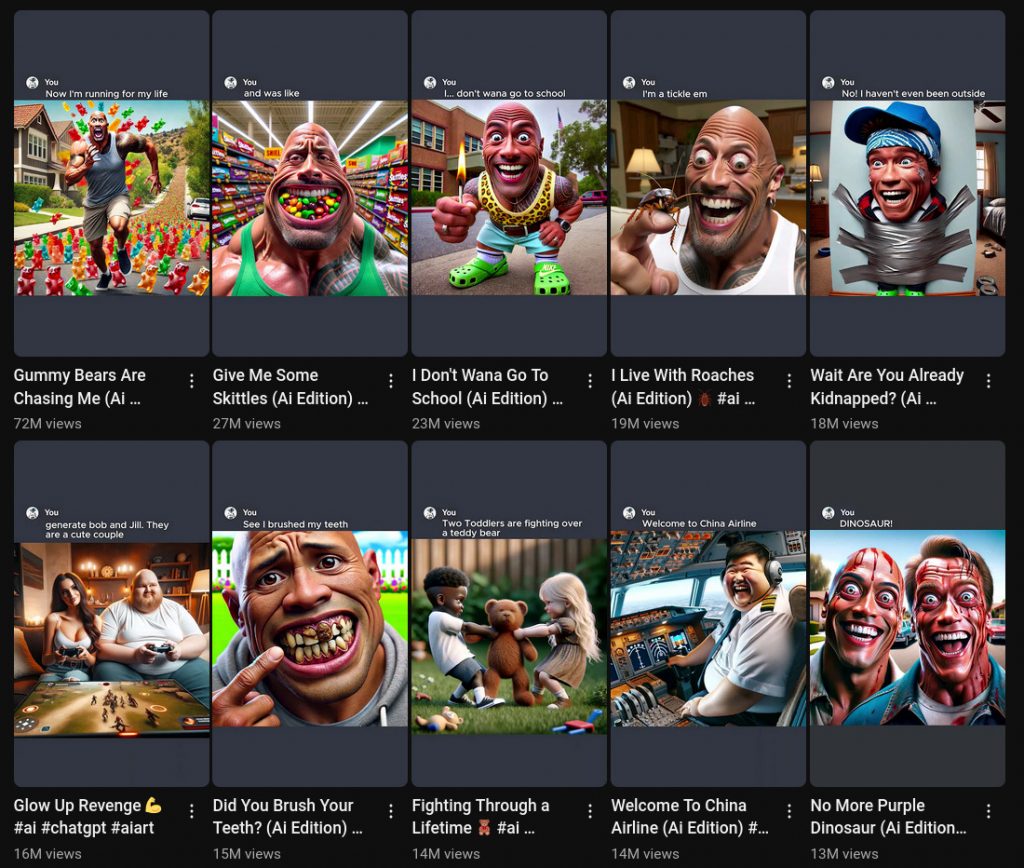
Facebook started as a way to talk with your friends, then turned into a feed of nearby activities and people you may be interested in, and now has morphed into a bottomless feeding trough of hyper-optimized machine-crafted AI slop which numerically speaking is more addictive than most psychotropic drugs.
I have like five hundred of these images but I’ll spare you the rest of them. Some are funny, others are horrifying.
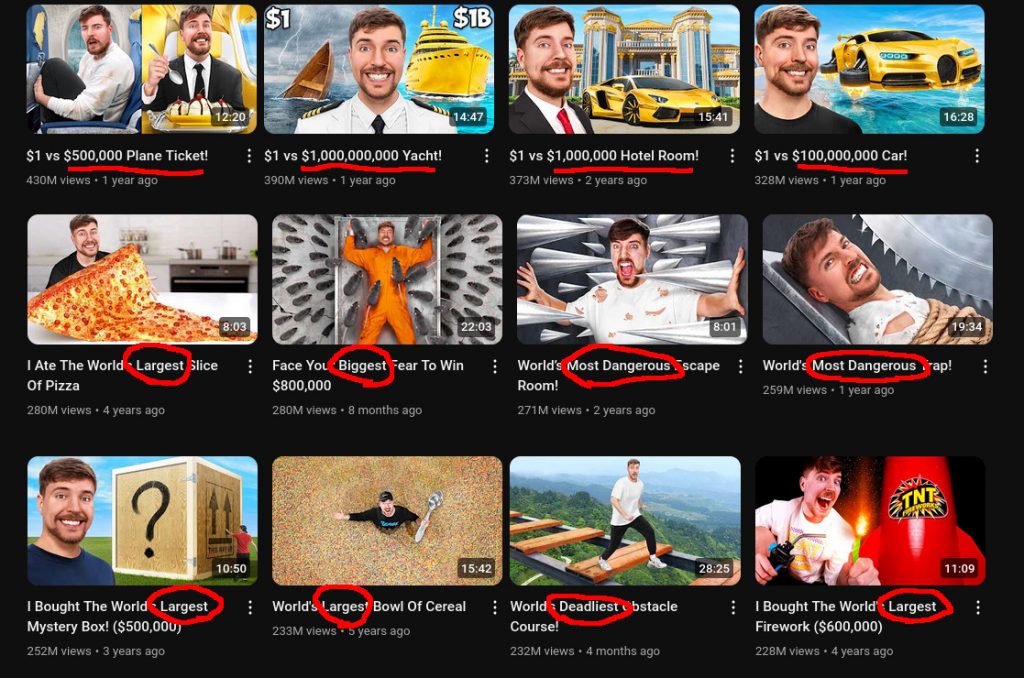
The same pattern repeats in other areas – Youtube started as a way to view short funny videos (after the dating app shtick at least), then transformed into long-form content with maximally-alluring thumbnails of things which don’t actually exist, and has now ascended into its final form of a superlative-maximization machine the likes of which you absolutely wouldn’t believe without first watching a thirty-minute video sponsored by NordVPN and AG1 (which are themselves strongly decohered from reality – almost all their marketing claims are lies). Youtube does have troves of beautiful music and enlightening education, but the latter represents a minority of time spent on the platform.
One of the best Youtube success strategies is to master the Art Of the Superlative Source: Mr Beast
Short-form video is an even more pernicious example of the results of content hyper-optimization. When I open Youtube shorts in a fresh session (no accounts or cookies) most of the videos fed to me seem to have nothing to do with reality whatsoever. There are so many layers of decoherence that if all I was given to learn about humanity was youtube shorts, I would understand virtually nothing of the human experience.
Some results when searching for short-form content with ‘AI’ in the title. Source
Anyone paying the least bit attention to popular meme culture among the youth over the last decade has likely noticed the drastic increases in surreality, artificiality, meta-humor, anti-humor, layers of abstraction, and shortening attention span, both of the users themselves and of the cultures which so graciously permit such alien psychofauna to inhabit their collective minds.
I can’t believe Jean Baudrillard predicted swedish fish-flavored oreos
There’s currently two remaining categories of popular short-form videos which have coherence with reality. The first is music (primarily human-made as of writing this, but the curve is bending quickly and this will not last long) and the second is what I refer to as “SFW pornography”.
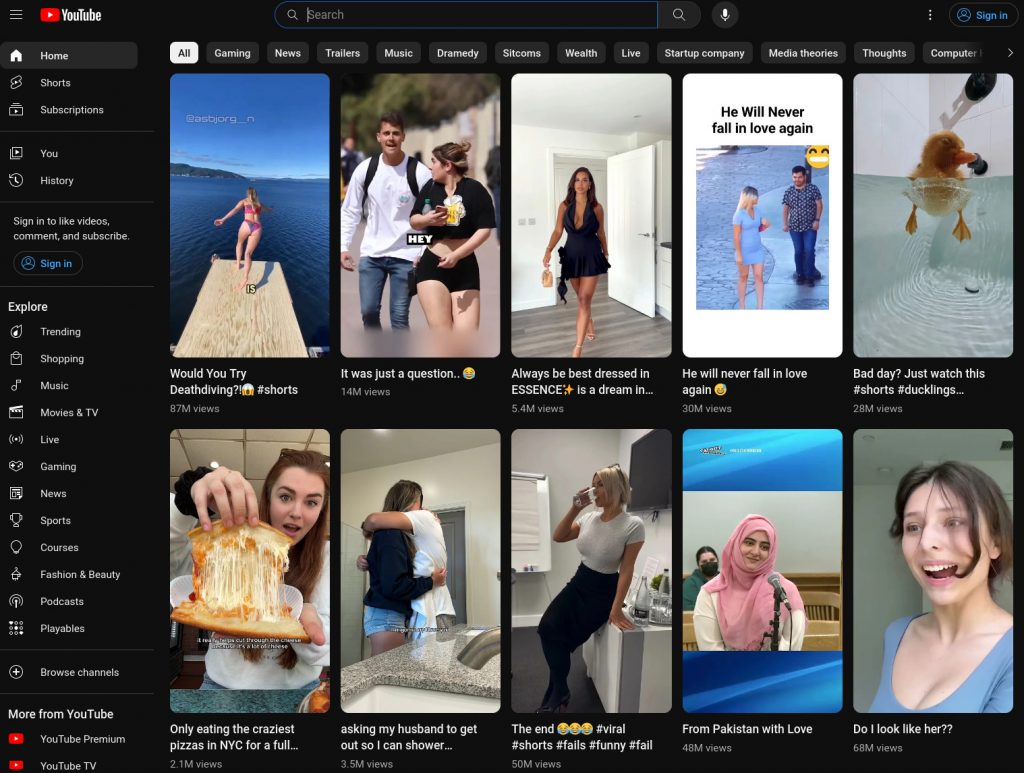
A large fraction of short-form video content is the latter. For some reason this surprises some people. To illustrate the point, below is a screenshot I took of a fresh Youtube shorts session (no account, no cookies, no view history). Take note that the proportion of videos which feature young women in a sexually-suggestive manner is greater than half. Instagram and Tiktok are similar. Most of them involve real humans for now, but this won’t be the case in the future.
I regularly open different social media apps with no account to see what they try suggesting to new users. Sometimes I play bingo with it. It’s easy to score a bingo.
What’s unique about the genres which have required less morphosis to remain memetically competitive is that they best exhibit content that is the equivalent of anti-meditation.
Meditation is often associated with sustained attention, introspection, and heightened awareness. You’re able to become introspective, to figure out what you truly are, what you truly want, and how you should act in order to attain these things (or in many cases, yes, how to not want things to begin with). But all styles of meditation involve sustaining a type of mindset for extended periods.
By forcing the viewer’s brain to continually context-switch rapidly while constantly inducing redirections of their conscious awareness (think: arrows, sound effects, fast camera movements, pop-ups, etc), watching short-form video is the opposite of meditation: it is anti-meditation.
Your gradients will rapidly update in ways you are barely aware of and your time will pass quickly with nothing of note improving about your life whatsoever. I don’t think addictive apps are inherently bad, but I’d at least prefer they were pleasurable or strengthening rather than neither.
IV. Consumption of decohered content results in decohered people and cultures
You become the average of the five people you spend the most time with. These five people don’t have to be next to you. They can be youtubers, twitch streamers, or twitter users. They can also be AI chatbots, vtubers, anthropomorphic animals, or Chinese content farms.
Because the nature of these five people consumers spend the most time with becomes increasingly decohered from reality over time, the resulting person also becomes increasingly decohered from reality over time.
The goal of all digital content is to personality-capture you into becoming the type of person that wants to consume more of it. The combined ecosystems of millions of intelligent programmers and AI researchers paired with millions of content creators is becoming quite good at this!
Due to human genetic and environmental diversity, we should also expect that the optimal content for each person to consume is wildly different. So we should expect there to be less of a global culture and fewer shared values over time and users slowly get siloed into their own walled gardens of bespoke content. The things that most people think are important and are “happening” in the world will decohere further and further until they are 100% artificial. We’re a little bit of the ways into this now, but the slope of the curve is going to increase a lot from 2025-2030, if we last that long.
There’s an unfinished section here where I want to talk about neurology for a bit, specifically with a focus on NMDA receptors, which will help make some of the predictions after this section more straightforward.
It’d be no fun if I posted a strong hypothesis without concrete predictions, so here’s a list:
The preferences of men and women will continue to strongly diverge, as optimal digital content is wildly different for each
The percentage of those identifying as LGBTQ will increase, transgender (m->f) rates will double at least two more times
The percentage of people identifying as furries, weeaboos, otherkin, plural, etc, will increase
There will never be any such thing as a unifying culture or cause in the future, with the only three potential exceptions being war, x-risk, and wireheading
The distribution of wealth and agency will skew even higher in free-market countries such as the United States
The rate of this skew will increase, and we will probably end up with a few very small groups of people who are largely responsible for deciding which direction humanity is going in (some of these groups / individuals are currently known, and I know who a few future ones will be, but the point is that the ratio of those in control to those not will get extremely small)
The fertility rate will continue dropping. most government interventions will not change this and neither will gametogenesis, although ectogenesis might depending on the type of government at the time
The financialization and tokenization and memecoinization and so on of things will drastically increase, and regulations will increasingly lose out to stopping them, especially in countries like the US.
The percentage of US citizens who believe democracy works will decrease continually over time. Ultimately democracy will obviously not be a thing due to AI, but I’m not yet confident how this will play out.
I think there’s a pretty strong chance many countries collapse over the next decade or two, and it’s good to prepare for things like widespread anarchy, power outages, etc. I wish I had specifics here but it’s simply not possible to make such predictions. At least, not yet.
A lot of other takes on AI which I want to finish at some point, but it’s a bit premature for me to fully post them. This bullet point is a placeholder for future-me.
There’s many other disciplines I want to cover here, especially that of governance, information propagation, the baseline ‘human’ condition, and much more. Unfortunately I spend a lot of my time with my company now so I have less time to read and write than I wish
So, what to do about all of this?
A few things come to my mind:
You want to have allies. People that you vibe with who you can rely on and trust in a crisis.
You want to practice memetic immunity. If you can’t close Twitter or Tiktok for more than an hour, you need to learn how to do this (at least if you want coherence with reality in the future. but you should retain optionality, in my strong opinion)
You probably want to be an early adopter of new technology, but only if you are good at 2) above. If you are not good at 2), you will be one-shot and eaten alive by the markets, and it is best to find a log cabin in the middle of nowhere to retire to.
You want to be anti-fragile. Are you prepared for shit to get real? “What type of shit?”, you ask. This means you are not prepared. None of us truly are though, so maybe that’s okay.
You might want to have a lot of capital, as the leverage you can attain with it will increase over time. I’m really uncertain of this point, but all else equal, it’s unlikely to hurt.
You most definitely want to have a high reputation and strong integrity. Being trusted and not defecting is far more important than making a quick buck. Perhaps infinitely so in the future.
This post isn’t fully finished, but I’ve decided to post it unlisted for now. Comments welcome.
The bouba/kiki effect is the phenomenon where humans show a preference for certain mappings between shapes and their corresponding labels/sounds. Note: this post is from 2021, and likely seems much less novel whenever you’re currently reading it.
One of the above objects shall be called a bouba, and the other a kiki
The above image of 2 theoretical objects is shown to a participant who is then asked which one is called a ‘bouba’ and which is called a ‘kiki’. The results generally show a strong preference (often as high as 90%) for the sharply-pointed object on the left to be called a kiki, with the more rounded object on the right to be called a bouba. This effect is relatively universal (in languages that commonly use the phonemes in question), having been noted across many languages, cultures, countries, and age groups (including infants that have not yet learned language very well!), although is diminished in autistic individuals and seemingly absent in those who are congenitally blind.
What makes this effect particularly interesting is less so this specific example, but that it appears to be a general phenomenon referred to as sound symbolism: the idea that phonemes (the sounds that make up words) are sometimes inherently meaningful rather than having been arbitrarily selected. Although we can map the above two shapes to their ‘proper’ labels consistently, we can go much further than just that if desired.
Which is a takete, and which is a maluma? Only you can decide.
We could, of course, re-draw the shapes a bit differently as well as re-name them: the above image is a picture of a ‘maluma’ and a ‘takete’. If you conformed to the expectations in the first image of this section, it’s likely that you feel the maluma is the left shape in this image as well.
We can ask questions about these shapes that go far beyond their names too; which of these shapes is more likely to be calm, relaxing, positive, or explanatory? I would certainly think the bouba and maluma are all four of those, whereas the kiki and takete seem more sharp, quick, negative, or perhaps even violent. If I was told that the above two shapes were both edible, I can easily imagine the left shape tasting like sweet and fluffy bread or candy, while the right may taste much more acidic or spicy and possibly have a denser and rougher texture.
Sound symbolism
The idea that large sections of our languages have subtle mappings of phonemes to meaning has been explored extensively over time, from Plato, Locke, Leibniz, and modern academics, with different figures suggesting their theorized causes and generalizations.
Some of my favorite examples of sound symbolism are those found in Japanese mimetic words: the word jirojiro means to stare intently, kirakira to shine with a sparkle, dokidoki to be heart-poundingly nervous, fuwafuwa to be soft and fluffy, and subesube to be smooth like soft skin. These are some of my favorite words across any language due to how naturally they seem to match their definitions and how fun they are to use (more examples because I can’t resist: gorogoro may be thundering or represent a large object that begins to roll, potapota may be used for dripping water, and kurukuru may be used for something spinning, coiling, or constantly changing. There are over 1,000 words tagged as being mimetic to some extent on JapanDict!).
For fun I asked some of my friends with no prior knowledge of Japanese some questions about the above words, instructing them to pair them to their most-likely definitions, and their guesses were better than one would expect by random chance (although my sample size was certainly lacking for proper scientific rigor). The phonestheme page on Wikipedia tries to give us some English examples as well, such as noting that the English “gl-” occurs in a large number of words relating to light or vision, like “glitter”, “glisten”, “glow”, “gleam”, “glare”, “glint”, “glimmer”, “gloss”. It may also be worth thinking about why many of the rudest and most offensive words in English sound so sharp, often having very hard consonants in them, or why some categories of thinking/filler words (‘hmm’… ‘uhhh…’) sound so similar across different languages. There are some publications on styles of words that are found to be the most aesthetically elegant, including phrases such as ‘cellar door’, noted for sounding beautiful, but not having a beautiful meaning to go along with it.
Sound Symbolism in Machine Learning with CLIP
I would guess that many of the above aspects of sound symbolism are likely to be evident in the behavior some modern ML models as well. The reason for this is that many recent SOTA models often heavily utilize transformers, and when operating on text, use byte-pair encoding (original paper). The use of BPE allows the model to operate on textual input smaller than the size of a single word (CLIP has a BPE vocab size of 41,192), and thus build mappings of inputs and outputs between various subword units. Although these don’t correspond directly to phonemes (and of course, the model is given textual input rather than audio), it’s still likely that many interesting associations can be found here with a little exploration.
To try this out, we can use models such as CLIP+VQGAN or the more recent CLIP-guided diffusion, prompting them to generate an image of a ‘bouba’ or a ‘kiki’. One potential issue with this is that these words could have been directly learned in the training set, so we will also try some variants including making up our own. Below are the first four images of each object that resulted.
four images of “an image of a bouba | trending on artstation | unreal engine”
four images of “an image of a kiki | trending on artstation | unreal engine”
The above eight images were created with the prompt “an image of a bouba | trending on artstation | unreal engine”, and the equivalent prompt for a kiki. This method of prompting has become popular with CLIP-based image generation models, as you can add elements to your prompt such as “unreal engine” or “by Pablo Picasso” (and many, many others!) to steer the image style to a high-quality sample of your liking.
As we anticipated, the bouba-like images that we generated generally look very curved and elliptical, just like the phonemes that make up the word sound. I have to admit that the kiki images appear slightly less, well, kiki, than I had hoped, but nonetheless still look cool and seem to loosely resemble the word. A bit disappointed with this latter result, I decided to try the prompt with ‘the shape of a kikitakekikitakek’ instead, inserting a comically large amount of sharp phonemes all into a single made-up word, and the result couldn’t have been better:
the shape of a kikitakekikitakeki | trending on artstation | unreal engine
Having inserted all of the sharpest-sounding phonemes I could into a single made-up word and getting an image back that looks so amazingly sharp that it could slice me in half was probably the best output I could have hoped for (perhaps I got a lucky seed, but I just used 0 in this case). We can similarly change the prompt to add “The shape of” for our previous words, resulting in the shape of a bouba, maluma, kiki, and takete:
the shape of a bouba (top left), maluma (top right), kiki (bottom left), and takete (bottom right)
It’s cool to see that the phoneme-like associations within recent large models such as CLIP seem to align with our expectations, and it’s an interesting case study that helps us imagine all of the detail that is embedded within our own languages and reality – there’s a lot more to a word than just a single data point. There’s *a lot* of potential for additional exploration in this area and I’m definitely going to be having a lot of fun going through some similar categories of prompts over the next few days, hopefully finding something interesting enough to post again. If you find this topic interesting, some words you may want to search for along with their corresponding Wikipedia pages include: sound symbolism, phonestheme, phonaesthetics, synesthesia, ideathesia, and ideophone, although I’m not currently aware of other work that explores these with respect to machine learning/AI yet.
Thanks for reading! I appreciate feedback via any medium including email/Twitter, for more information and contact see my about page
This Anime Does Not Exist was launched on January 19th 2021, showcasing almost a million images (n=900,000 at launch, now n=1,800,000 images), every single one of which was generated by Aydao‘s Stylegan2 model. For an in-depth write-up on the progression of the field of anime art generation as well as techniques, datasets, past attempts, and the machine learning details of the model used, please read Gwern’s post. This post is a more concise and visual post discussing the website itself, thisanimedoesnotexist.ai, including more images, videos, and statistics.
The Creativity Slider and Creativity Montage
Previous versions of ‘This X Does Not Exist’ (including anime faces, furry faces, and much more) featured a similar layout: an ‘infinite’ sliding grid of randomly-selected samples using the javascript library TXDNE.js, written by Obormot. Something more unique about Aydao’s model was that samples remained relatively stable, sometimes significantly increasing in beauty and detail as the ‘creativity’ value (see: psi) was increased all the way from 0.3 to 2.0. This led to the creation of the ‘creativity slider’ as well as linking every image to a page with a tiled layout showing every version of the image:
“The more entropy you give me, the more it makes me want to smile!”, 18 samples of image # X from creativity 0.3 to 2.0
One of the best and most common effects of higher creativity is better colorization, including shading, reflections, vibrancy, color diversity, and more
Another tile of seed 7087, showcasing stability with an increasingly interesting artistic style and details
Although the above two are among my favorite examples of creativity montages, many users found some other interesting things that increased creativity could do:
Sometimes it appeared as if ‘creativity’ was simply an alias for the increase in volume of a certain bodily area coupled with a proportional reduction of garment-covering surface area (seed 30700)
Sometimes increased creativity also leads to mitosis (seed 28499)
Sometimes you get… a lot of mitosis?
Selected artwork
The best way to demonstrate the stunning potential of this model is to show some of the samples that users have enjoyed the most:
The original thumbnail image for This Anime Does Not Exist: “Notice me, Onee-chan!”
Other earlier candidates considered for the website’s thumbnail (seeds: 1013, 4606, 8674, 8859)
Incidentally, it also seems that users love sharing images that are not the most beautiful, but the weirdest as well. The below four were among the most popular images on the website during the first few hours, when there was only n=10,000 of each image:
A montage of the interesting and popular results from images 3313, 7820, 4437, and 3103. Sample 3103 would be a particularly good album cover for a death metal band.
Collapsed images
Sometimes the result collapses enough to lead to an image that, although pretty, does not at all resemble the ideal target:
interesting but unintended results from samples 0544, 31975, 3997, 0557
Writing
In many cases the model will produce writing which looks distinctly Japanese, however upon closer introspection, is not legible, with each character closely resembling distinct counterparts in Japnese scripts, however diverging just enough to produce confusion with a lingering feeling of otherworldlyness.
Although some characters are easily recognizable, many are not, and are nonetheless *usually* combined in incoherent manners
Videos and gifs
As it’s possible to produce any number of images from the model, we can also use these images to produce videos and animated gifs. The primary style of this is referred to as an interpolation video which is produced by iterating through the latent variables frame by frame, transitioning in between different samples seamlessly:
Additionally, I decided to make a few videos that used a constant image seed, but modified only the creativity value instead (instructions on how I did this are here):
I chose this particularly wholesome sample to demonstrate a gif with creativity 0.3-2.0 and a frame difference of 0.01
Statistics and users
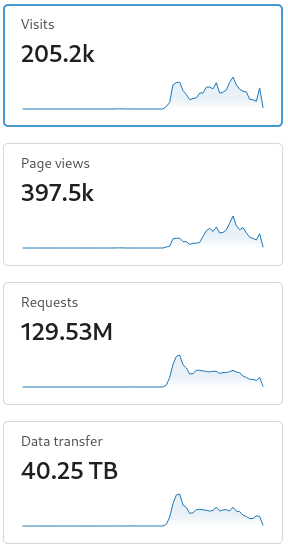
After the first day, the website had served over 100 million requests, using over 40TB of bandwidth:
First-day traffic statistics from CloudFlare’s Traffic Analytics
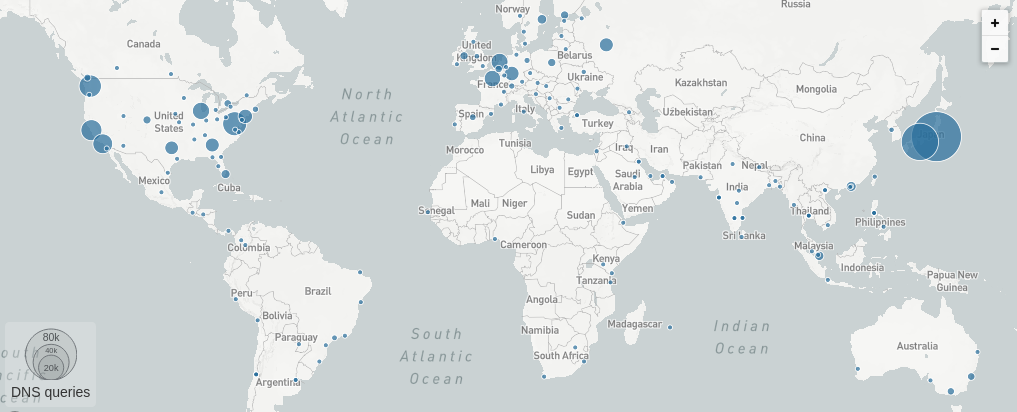
At launch, the largest contributor to traffic by country was the United States, followed by Russia, but over the next two days this quickly shifted to Japan.
A map showing which of Cloudflare’s data centers served the most DNS query results for the domain
Compare to similarly-trafficed websites, thisanimedoesnotexist.ai was relatively cheap, thanks to not requiring server-side code (serving only static content):
Domain ‘thisanimedoesnotexist.ai’: for two years from NameCheap: $110
Cloudflare premium, although not required, improves image load time significantly via caching with their global CDN: $20
Image generation: 1,800,000 images, 10,000 generated per hour with a batch size of 16 using a g4dn.xlarge instance, which has a single V100 GPU with 16GB of VRAM at $0.526 per hour on-demand: $95
“Accidentally” hosting the website from AWS for the first day, resulting in over 10TB of non-cached bandwidth charges: >$1,000 (via credits)
An image of what my desktop looks like while generating an additional million anime imagesWhat the access log for nginx looks like while serving >1,000 anime images per second
Yet another example of why to not use AWS for high-bandwidth content: AWS has some of the most expensive bandwidth at $0.09 per GB (luckily this was paid for entirely with credits and the migration off of AWS was complete in less than a day to a more sustainable provider)
Conclusions and the future
All in all, this was a fun project to put together and host, and I’m glad that hundreds of thousands of people have visited it, discussed it, and enjoyed this novel style of artwork.
If you want to read in-depth about the ML behind this model and everything related to it, please read Gwern’s post.
Thank you to Aydao for relentlessly improving Stylegan2 and training on danbooru2019 until these results were achieved as well as releasing the model for anyone to use, Obormot for the base javascript library used, TXDNE.js, Gwern for producing high-quality writeups, releasing the danbooru datasets, and and other members of Tensorfork including Gwern, arfa, shawwn, Skyli0n, Cory li, and more.
The field of AI artwork, content generation, and anything related is moving very quickly and I expect these results to be surpassed before the year is over, possibly even within a few months.
If you have a technical background and are looking for an area to specialize in, I cannot emphasize the extent that I’d strongly suggest machine learning/artificial intelligence: it will have the largest impact, it will affect the most fields, it will help the most people, it will pay the most, and it will cause you to be surrounded by the best and smartest people you could hope for.
Thanks for reading and I hope you enjoyed the website! For more about myself, feel free to read my about page or see my Twitter.