Personality basins are a mental model that I use to reason about humans within their environment: from modelling why people are they way they are, how they change over time, how mental illnesses and addiction function along with how we should look for their cures, and how the attention economy optimizes itself to consume all of your free time.
What is personality?
Note: This post contains many analogies to concepts from deep learning. Please do not interpret these comparisons too literally!
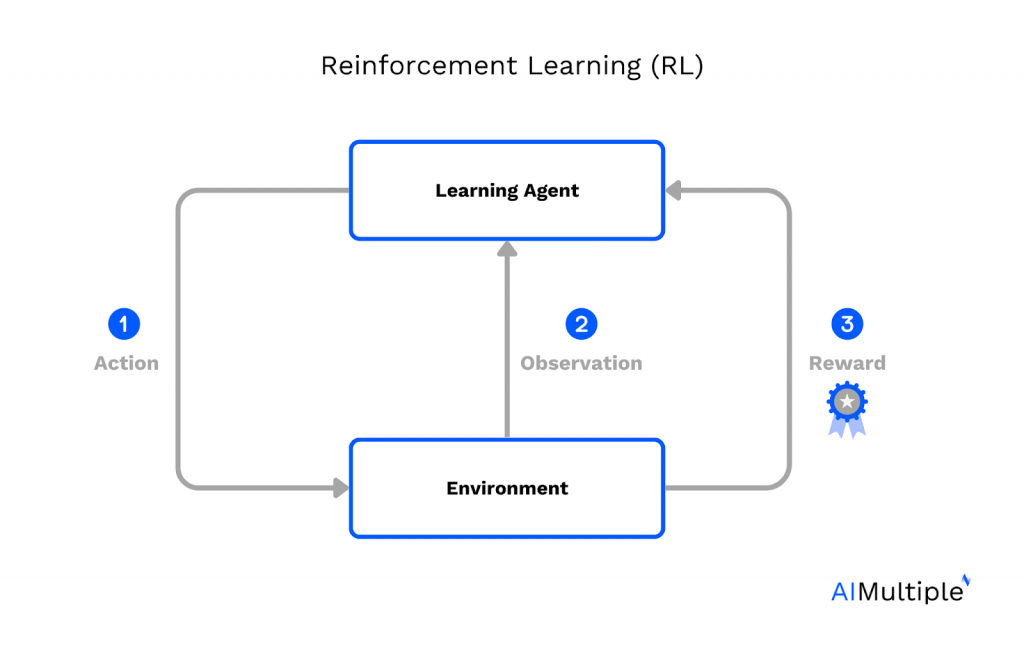
Your personality is formed by a process conceptually similar to RLHF. You are first born with a set of traits in a given environment. After this, you perform many interactions with your environment. If an interaction goes well, you’re likely to do it more often, and if it goes poorly, you’ll probably do less of it.
See the learning agent? That’s You! If your interaction with this post goes well, you’re likely to read more of them later.
If you were born tall and with a commanding voice you might find that you get what you want by confidently demanding it, and this will help to result in a confident personality. If you attempt this strategy as someone born small with a soft voice, it will probably have weaker results and encourage you to try something else out instead.
Genetics has a large influence on most traits including personality. This topic is outside of the scope of this post: it is best to think of this post as providing some scaffolding for the question of “why is this person X, when they could have instead been Y if they had been in a different environment” or “what helps to explain the differences in outcome between two genetically identical people” (see also: niche construction and gene-environment correlation).
Periods of high social and environmental entropy during adolescence are the most formative because you will learn the most information about which actions perform well in your environment and which don’t (of course, our meta-learning algorithm knows this, and this is why you have higher neuroplasticity and thus a higher learning rate and more energy during this period. It’s time to learn how to succeed in your newfound environment!)
Your personality basin
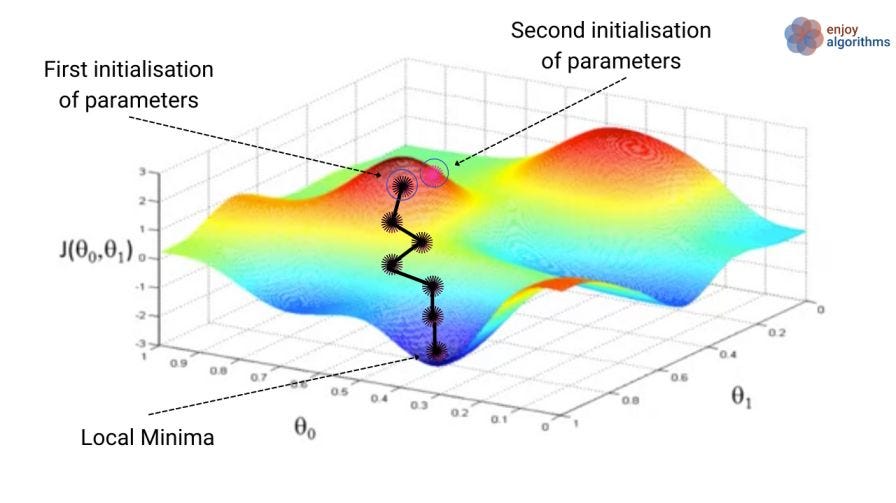
As you go about your life, you will continue to modify your personality in response to your environment, and eventually you will end up in something that resembles a basin. Maybe you were born tall and attractive and then this led you to engage in a lot of athletic activities and socialization, and at the end of all of the positive feedback you have ended up with a jock personality that goes on to become a professional football player.
This is a landscape of personalities. The black line is your personality over time, and the last point is the person you currently are. Just like in machine learning, the way that you’ve progressed as a person has been by trying out many things and then doing more of the things that worked well.
If instead you grew up scrawny yet intelligent you might have found things go well for you when you adopt a more quiet persona and focus on solving technical problems in programming or mathematics, perhaps eventually leading to a career as a software engineer or academic. Just like training a model in machine learning, the general gist is that you will try out a lot of things and then do more of the things that went well.
The above image is of a loss landscape in machine learning. Since we are discussing personality, all of the points on the landscape represent different personalities you could have, with the lower points being personalities which are more successful. The personality basin that you find yourself in solidifies over time as you find out who you are and choose your friend group, career path, social and aesthetic preferences, and so on.
Most personality changes are unconscious
Most of your movement within personality-space happens outside of your conscious awareness. Although there are many times in life you’ll consciously decide to act in a certain way, this is the exception, not the norm. Your brain is always making millions of gradient updates a day based on what is and isn’t going well and often the most you can do is try to be as observant as possible. This is why techniques like nonviolent communication, dialectical behavior therapy, and mindfulness have observation and introspection as a core facet, because it’s something that you have to consciously practice to become good at rather than something you’re born with.
Most addictive behaviors start without us noticing what is happening until we are sufficiently addicted such that the habit is hard to break. Relatedly, if you introspect on many seemingly-innate preferences you will often notice some of the environmental and social gradients that have helped shape them. An interesting thought experiment you can perform on yourself is to pick a random personality trait that you have and try to answer the questions “why am I like this? could I imagine a version of myself that is not like this, and if so, what happened differently to them?”
Many people think their music and fashion preferences are innate to them and are solely based off of how their favorite music sounds and their favorite outfits look. But if their most hated political party (or often in the case of adolescents, their parents) adopted the same aesthetic preferences, you can imagine they might start to literally like them less!
Your conscious experience of a stimuli is not dictated by a single-variable function f(stimuli), but rather f(stimuli, personality, environment), for broad definitions of ‘personality’ and ‘environment’. If you have a favorite song that your friend thinks sounds terrible, this is because they are literally experiencing it differently from you due to the latter two variables given to this function. They don’t think the thing that you hear sounds terrible, they think the thing that they hear sounds terrible, and it is probably very dissimilar from what you hear. The average conscious experiences of most people are likely wildly different from one another (see also: What Universal Human Experiences Are You Missing Without Realizing It). For more thoughts on the signaling, environmental, and self-deceptive aspects here I’d suggest reading about signalingtheory and checking out The Elephant in the Brain by Robin Hanson and Kevin Simler.
How do you know if you’re in the right basin?
If you’re reading this you probably have a vague idea of what type of personality basin you’re currently in which you can recall by asking yourself the question “What type of person am I?” But an important question remains: how can you find out if this is the right basin to be in?
A simple answer would be that you could try out other basins to see how they feel. Maybe you’re having a great life as a devops programmer, but you could try to become an artist or a woodworker or a stay-at home parent and see how that fares for you.
The reason why this is hard is that the optimal personality for this basin is not immediately accessible to you – to truly test optimality you will need to go through a full RLHF process. If you want to know how good of a life you’d have as a professional pianist, you will have to practice the instrument for a decade to find out.
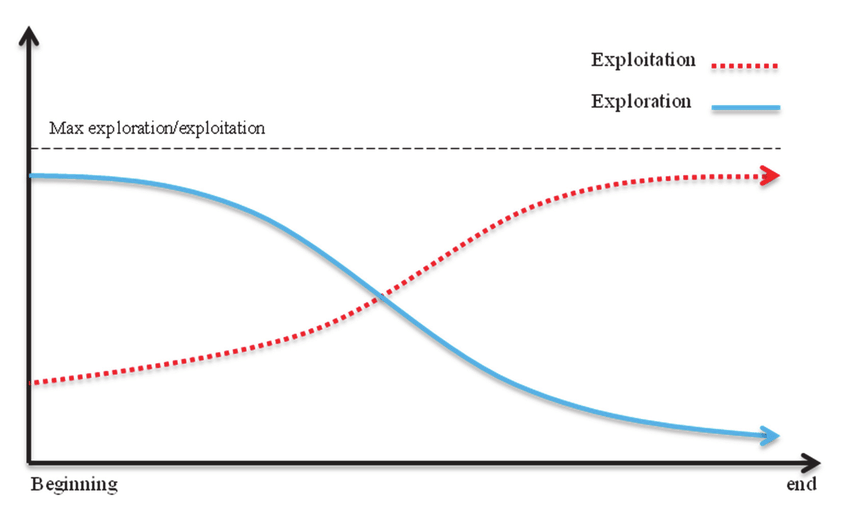
You may wonder if you could simply try your hand at the piano for a month or two and see how it goes, and of course you can do this too. Your time (and your meta-learning algorithm’s number of epochs and learning rate) is limited, and it’s reasonable to make the trade-off of sacrificing depth-first search in favor of more breadth-first search.
As you progress in life, you will usually perform less exploration for new personalities and more exploiting with your developed personality
Usually this breadth-first search of trying out many different and creative strategies for life (prioritizing exploration over exploitation) automatically happens during your adolescence, but one of the magic things about the modern world is that there are so many societies, cultures, countries, and fields of work one can move into, and for each different environment could exist a slightly-different-you which finds their own distinct personality that maximizes success. Had you been born as a hunter-gatherer or within the Roman Empire or in ancient China, you’d probably have ended up quite different as a person. Similarly, if you decide to move countries or communities or careers, the optimal-you-for-your-environment will change a lot too.
Personality-space is adversarial
One interesting thing to note about personality-space is that it is adversarial. Rather than a static training set to iterate through, your training data consists of other RL agents, many of which are other people, and all of whom want different things from you.
This is what leads to the concept of Personality Capture. Personality capture is when your environment RLHFs you into becoming a personality that benefits the agents around you rather than yourself.
If a school bully threatens to hurt you unless you do their homework for them, they are attempting to modify your RLHF process so that it results in an agent which is beneficial to them, hopefully resulting in someone who will always give in to their demands.
Those familiar with high school psychology will find high similarity with this concept and that of classical and operant conditioning as well as concept of a Skinner box. The attempted addition to these concepts here is that of modelling the personality as a reinforcement learning process and changes in personality as gradient updates, which then allow us to view personality-space as a high-dimensional area which will give us some interesting tools to think with. As the saying goes, all models are wrong, but some are useful.
Luckily for humans there exist many symbiotic equilibria where multiple parties can find mutually-beneficial feedback loops within the epochs of personality-space. Parent/child relationships, marriages, and best friends are often good examples of such a situation.
Personality Capture
It’s easy to become susceptible to various forms of personality capture when your environment changes. When asked why he isn’t on Twitter, Dario Amodei, CEO of Anthropic, responds to Dwarkesh Patel with:
I’ve just seen cases with a number of people I’ve worked with, where attaching your incentives very strongly to the approval or cheering of a crowd can destroy your mind, and in some cases, it can destroy your soul.
I’ve deliberately tried to be a little bit low profile because I want to defend my ability to think about things intellectually in a way that’s different from other people and isn’t tinged by the approval of other people.
Illustration of a monkey being personality captured by excessive twitter usage
Most people around you want to personality-capture you in some way. Your boss might want you to work harder, your children might want you to give them more attention, and political parties want you to vote for them. Some of these things will be beneficial for you as well, but it’s easy to get trapped into bad habits when your adversary is sufficiently motivated and intelligent (e.g. social media feeds).
One interesting way to frame personality capture is by combining it with the concept of attention economics. All of the apps on your phone want to turn you into the type of person that uses them all day because that is beneficial for their revenue models. In many cases this is mutually beneficial, but it’s nonetheless clear that the cat and mouse game is starting to favor the felines more and more over the last two decades as they have learned to perfect their craft of user acquisition, retention, and ARPU maximization.
As I discussed in where are the builders, the game becomes particularly skewed when there is a large difference in ability or judgement between counterparties, with one common example being children and adolescents. It’s easy to become personality-captured by minecraft or roblox at the age of 10 – such games are not only fun and addictive, but a child also has little understanding of the level of optimization their counterparty has put in to making sure that they remain a user for life. The reason it’s so hard to put your phone away is because it’s a battlefield of yourself versus thousands of intelligent and well-compensated engineers trying their hardest to ensure you do just the opposite.
How do I leave my personality basin?
Perhaps you have decided that you don’t like your personality basin. Maybe it used to be working out for you but no longer is, or maybe you’ve always been unhappy with it. Or maybe you just have reason to believe you’re trapped in a local maxima which is far inferior to the global one. What should you do?
The first thing you’ll want to do is to change your environment. If both you and your environment are a constant, you shouldn’t expect to end up in a different basin any time soon. For every new environment exists a new optimal-you, and the world offers many environments to choose from.
The second thing you’ll want to do is increase your learning rate. There are a lot of ways to do this. One interesting note is that your learning rate will automatically increase if your environment changes. This may be why so many people find they are able to be more thoughtful and creative while going on long walks in nature rather than sitting in a cubicle.
This is also a reason why it’s good to constantly be trying new things, because new things will likely involve new environments and new people. If you wonder why trying new things is hard, it is likely because this trait was more maladaptive in our ancestral environment than it is today, as we had less control over our surroundings in the past (If anything, we may have too many options in some cases of the present: our society is so large that defection from a group is less costly as you can simply find a new group to join afterwards. This seems to create challenging game-theoretic equilibria in match-making where commitment to a partner is devalued due to the ease of finding alternatives, the effects of which can be seen by how discontent much of the population is with dating apps).
A common mistake in life is to let your personality basin solidify too early. Your parents and schooling environment have a disproportionately large influence on who you become as an adolescent. But as soon as you gain the freedom to act independently as an adult, it’s usually a good idea to force yourself to try as many new things as you can, including moving cities (or countries!) and considering drastically different lines of work. Even if you feel content with where you are, the potential return is literally life-changing. Moving away from where I was born was one of my most important life choices, but it still took me several years longer than it should have to give it a shot.
Although you have a general learning rate curve for how quickly your personality adapts to a new environments, different stimuli will also be paired with differing gradient magnitudes. High-magnitude experiences which result in strong gradient updates can move you within personality space much more quickly.
Humans have many sets of learning rate curves which govern different parts of their brain. In addition to the baseline learning curve, our learning curves are heavily modified by our environment.
If someone uses a psychedelic drug which explicitly gives them high-magnitude gradients they will probably move a lot more in personality space than if they had stayed sober. Similarly if someone undergoes a highly traumatic event, it may push them a long distance within personality space as they quickly adapt to ensure that they don’t have to go through the same experience again. Both of these activities involve large gradient updates.
Common activities which seem to give the largest gradient updates to humans are meditation, drug usage, trauma, religious events, love, gambling, and sex.
Some of these concepts are more negatively-coded than others, for example trauma. But the intended purpose of trauma is obvious, which is to avoid really bad things from happening to you in the future. One of the reasons why overcoming trauma isn’t as hard-coded into us as strongly as we might hope for is because our present society is so much larger than that which we evolved in such that there’s more opportunity to change your environment as to remove the potential source of trauma. Trauma was likely more adaptive in our ancestral environment than it was today due to an inability to drastically change your surroundings and social group in the past.
This is why strong psychedelic drugs like ayahuasca can be dangerous: whatever happens to you during your experience will be fed to you via high-magnitude gradients. Because users may experience hallucinations and delusional thinking during usage of such drugs, it’s possible for their location in personality-space to be thrown far out-of-distribution and into an area which has little overlap with the rest of humanity (See also: Psychedelics reopen the social reward learning critical period; Ketamine: ~48 hours, Psilocybin/MDMA: ~2 weeks, LSD: ~3 weeks, Ibogaine: ~4 weeks).
This isn’t to say there can’t be high-magnitude positive outcomes as well, but just that there is a high potential for variance when large gradients are involved. Romantic love can be a similarly dangerous force and has pushed thousands to suicide, yet our society near-universally regards it as a good thing! While there are many other reasons for this, high-variance is not inherently bad and is likely necessary at the societal level in order to promote long-term antifragility (this is also the very reason I am so bullish on America).
Personality basins and mental illness
Personality basins are an interesting way to model many mental illnesses. Similar to attractor states or trapped priors, they allow us to have a simple model with which we can plan to manipulate in order to solve our problems. Just as your personality basin decides how introverted you are, how funny you are, and what type of music you enjoy, it also helps to curate which psychiatric conditions affect you.
One of the reasons why curing depression is so hard is because you need a very large gradient update to escape the basin you’re trapped in. This gradient update could come all at once via an excessively strong positive stimuli, for example a drug which explicitly increases your learning rate like ketamine. But this is often hard to reliably induce, and so the gradient updates instead usually have to be small and continual over a long period of time.
This is what most cognitive behavioral therapy techniques are: we find a simple way to make a small positive gradient update to push you ever-so-slightly out of the personality basin you’re trapped in, and then we keep doing it for months or years until we finally push you all the way out of the undesirable basin.
This is also a nice way to model something like drug addictions: drugs personality-capture you into a basin which feeds off of and depends on them, and this basin can become arbitrarily deep due to the high magnitude of gradients drugs can apply to you (and thus be very hard to escape from). The concept of relapsing on a drug is equivalent to falling back down to the bottom of the basin, and the concept of tapering off dosage over time is equivalent to providing small and continual gradient updates over time.
I have a lot of hot takes that society is collectively becoming so efficient at some forms of personality capture that we will end up inducing various psychiatric conditions in the majority of our population. Societies end up with their own hyperdimensional personality basins just as people do, and just like us, the two ways they can move out of their basin are either gradually via many slow updates (e.g. the industrial revolution), or all at once via a very strong update (e.g. the french revolution). It’s worth thinking about the effects that different types of memetic information may have on our society’s collective personality basins as we become more and more efficient at communication.
Can’t I be in multiple personality basins?
One thing you may notice from the above sections is that your personality appears much more malleable and dynamic than one described by a static point: you probably act differently around your family than you do around your friends or your co-workers.
To solve this discrepancy you can simply model personality space and your personality basin with additional dimensions, allowing you to model yourself not as a 1d point, but as a three-dimensional landscape.
I model my own personality basin with an extra dimension (i.e., 4d): at any given point in time there exists a “me” which implements a given personality landscape in a given personality basin, but I also have many sub-basins which implement my different moods. The set of actions I might perform when I’m angry is very different from that when I’m sad, and these are simply different sub-basins within the containing higher-dimensional basin. You could similarly increment the model’s dimensionality in order to model yourself using internal family systems or even dissociative identity disorder.
Although the concepts presented in this post are similar to pre-existing ideas, I find that applying the analogy of loss landscapes, basins, and basic RL and DL concepts to be useful tools for thought and encourage readers to do further exploration with this mental model in case they find other useful analogies (what might a linear transformation on the loss landscape of personality-space look like and compare to? how can we develop a more comprehensive model of learning rate in humans and how we can modify it? are there any mental illnesses we can use this model with to try to come up with novel types of cures? how can we integrate this with bayesian theories of learning and perception? which other ideas in LLMs, RL or ML might we find useful to further analogize with?)
The explicit goal of this post is to help RLHF you into a personality basin which more easily allows for thoughtful analogies and practical tools for introspection. Try something new today you’ve never done before or spend some time with no distractions to think about yourself and others! If you liked this post consider checking out my home page or twitter. Feedback is welcome!
What are the brightest and most ambitious minds of our generation currently working on?
Here is a video from someone who spent 7 months building minecraft inside of minecraft by painstakingly constructing a redstone computer inside of it with its own graphics card and screen
Here is someone who spent 5 years constructing a 3D game within a 2D geometry game by building primitives and constructing 3D illusions from them
Here is a video from someone who spent 6 months building a factory inside factorio which recursively self-expands using a lua script
And here is someone who spent 4 months building a shader to let the linux kernel run inside of VRchat via writing a RISC-V CPU/SoC emulator in an HLSL pixel shader
I find the above examples fascinating from the meta perspective: while there’s nothing wrong with having fun building inside of games, these are the very same skillsets which tech companies would pay six figures to have on their side! (of course they may enjoy the games more – this is discussed later)
Sometimes people of this caliber even have trouble finding a job – they often don’t really know where to go besides apply online to boomer companies who reject them when they see a lack of credentials. They love building things and are very smart and hardworking, but their milieu is an environment which captured them from a young age (often a video game or social media) and sometimes also ensured that the value they produce is within a pre-existing platform (e.g. a video game).
“Why did you cherry-pick people playing video games instead of talking about, like, everyone currently enrolled in medical school or something?”
The US currently has 125,000 students enrolled in medical school (this seems low to me but I checked several sources). Minecraft has 140,000,000 (1120x) monthly active users. Roblox has 200,000,000 (1600x). This is obviously an unequal comparison, but the magnitude of the difference is still staggering.
Why are you building a graphics card inside minecraft instead of inside nvidia?
There’s several reasons why someone might build a graphics card inside of minecraft rather than being paid $300,000 a year to build one inside of nvidia:
Minecraft is more enjoyable
Minecraft is more addictive
Minecraft found them first
They don’t know the latter option exists, or how they would do it, or think they’d fail at it
The first reason (that minecraft is more enjoyable than working for nvidia) applies to most people who are playing games instead of working, and instead the latter three reasons will be the focus of the following sections.
Addiction & Adolescence
The world has a lot of addicting products. Most of them I’m able to avoid, but some of them just happen to hit my sweet spot: I had no problem avoiding smoking growing up, but world of warcraft consumed years of my adolescence.
Others don’t find world of warcraft addictive, instead procuring their poison elsewhere. Maybe it’s minecraft, or league of legends, or youtube shorts.
One of the reasons these apps out-compete the ‘real world’ is because they start competing for our attention at a very young age. Most kids will grow up inside of roblox, minecraft, discord, instagram, and tiktok. If a kid starts using their smartphone at 10, these platforms will have a full 8 years to solidify within their mind and modify their values and social network before they are even legally allowed to have a job. I refer to this concept as personality capture and have a post on personality capture and personality basins here.
Some comparisons to past historical figures:
Andrew Carnegie started working at a cotton factory at the age of 12
Henry Ford left home at 16 to work as an apprentice machinist
I would have killed for a tech internship when I was 14. I had no idea how I could do that, so I studied independently for my CCNA instead and would hop straight into video games when I got home. In hindsight it’s really interesting thinking about past-me playing these games, because I was young and knew so little about the world, yet my counterparty was hundreds or thousands of well-educated adults optimizing for my addiction and spend. It certainly wasn’t a fair battle!
Products induce strong preference modification
When I was 12, the highest-status person in the world to me was zezima. For the ~85% of readers who don’t recognize this name, he was the highest ranked player in runescape and had an aura of infamy that I can only compare to someone like elon musk. What I wanted most in life at this age was a party hat, which was an immensely valuable item in the game which most players could never afford even after years of play.
Many of our values are locally-set by our environment and peers, and when we immerse ourselves into a different world, our preferences change alongside it. This is pretty obvious – the twitter addict is constantly thinking about how many followers and likes they get just as the league of legends player is ever-ruminating over their rank and win ratio.
This is a fully general force too – If my friends and I only had a forest to play in growing up, we’d probably have invented some status game of who can climb the highest tree and would eventually have our own local culture, lexicon, and so on. But the forest is actually much easier to escape from than video games and social media – literally speaking.
I tried to find some user retention numbers for world of warcraft which I was heavily addicted to as a teenager and found a monthly churn of ~5%. In other words, the typical world of warcraft subscriber played the game for over a full year. I wonder if they knew when they clicked the sign up button that, statistically speaking, they would spend hundreds of dollars and over a year of their life playing? I certainly didn’t when I clicked the button at 13. It’s worth noting that the linked paper is a decade old and points to a time when we used spreadsheets to optimize addictiveness rather than machine learning.
That your preferences are locally induced is why the simple heuristic that you become the average of your five closest friends is so useful. If you get to choose your friends, you also get to choose many of your preferences and goals. Although I had the freedom to choose my friends at the time, quitting a game I loved was hard because unless my friends quit too, I’d have to go find new friends. Before this statement appears obviously fallacious to many readers, I need to add the necessary context that most people I knew in MMOs would also play them for ~100% of their free time, easily reacing 8-16 hours a day (yes, there’s a strong selection effect here). Although I had a ton of fun in my years inside these games, I always wondered what I’d have ended up doing if they hadn’t existed.
Agency in the free market
I’m writing this blog post at 1AM right now. In order to do so I’ve had to block twitter, close messenger, and set my phone to night mode. Luckily I’m not battling any video game or youtube shorts addictions, or this post wouldn’t exist. I don’t think I’d be able to sit down and write for hours if I had spent my entire adolescence on tiktok.
As consumer markets become more efficient and we become more skilled at capturing and retaining the attention of the populace, we should expect the average agency of society to decrease.
This is obvious if you think about it for a bit (the goal of almost every app on your phone is to get you to do less of anything which pattern matches ‘not using their app’), but there are few who appreciate the magnitude of this effect as the masses of society engrossed in video games and social media at home alone in their bedrooms every night are well-hidden from us. You can walk to the park to see 50 people enjoying the outdoors, but the millions currently scrolling tiktok at home are hidden from you in every way except via a statistic.
I love how easy generative AI makes it to learn – I sometimes talk to Claude until I’m exhausted and have to sleep. But in the free market, Claude doesn’t stand a chance against Tiktok. This post isn’t about Tiktok either though, as Tiktok doesn’t stand a chance against SuperTiktok (soon).
Outlier Success
Many have wondered why there’s fewer entrepreneurs in their 20s on a path to outlier success than there were in previous decades. Facebook IPO’d at a valuation of $104 billion when Mark was 28. Stripe reached a valuation of $35 billion when John was 29. Snapchat IPO’d at $24 billion when Evan was 25. These are outlier examples, but that’s the entire point. Where are the current outlier examples from the next generation?
I offer several potential answers:
They are currently busy playing video games (which likely become more important to them at a very young age)
They watched so much tiktok as a adolescent that they no longer have the attention span to build things (that would involve not using tiktok)
They have so little free time due to attention economics that they no longer have original ideas (time spent doing ‘nothing’ is very valuable for quality long-term life outcomes)
Many in the tech ecosystem call me a doomer when I suggest these explanations – they certainly aren’t addicted to video games, and their friends certainly don’t have reduced attention spans from tiktok. But they live in a bubble within a bubble (context: I work in AI in San Francisco), and from my point of view the data points to these hypotheses as strong contenders. Sometimes I talk about this with normal people and they think the above is so obvious that it doesn’t even interest them. Perhaps our future has always been that of bread and circuses?
To clarify – I don’t intend to say that consumption or video games are bad; I love both of them myself! But we may be getting too good at consumer app optimization, and when that is paired with adoption at a young enough age, the outcome is undesirable. Building minecraft inside of minecraft is cool, but when I see a toddler scrolling youtube shorts on an ipad alone I feel really bad.
As the agency of the average consumer decreases, the ceiling for the agency of outliers increases. Examples of inventions which drastically increased the ceiling of agency include venture capital, generative AI, programming, microchips, and trade and capitalism itself. Once AI agents start to actually work it seems like this will be another large driving force here. Many have wondered when the first one-person billion-dollar company will exist, and many predict it may be within just one or two decades. It will be an interesting time to be alive in, if nothing else.
memetic-invariant information remainsconstant in value if more people learn it
memetic-cooperative information becomes more valuable if more people learn it
memetic-competitive information becomes less valuable if more people learn it
Memetic-invariant
Most simple facts are memetic-invariant. That the sky is blue or that water takes the shape of its container continue to be true and have similar value no matter how many people learn it.
Memetic-cooperative
Sometimes we are lucky enough to discover memetic-cooperative information, which becomes more valuable the more people learn it. Most of our society is built upon the fact that memetic-cooperative information exists, is easily socially transmissible, and can lead to stable equilibria built upon common knowledge.
The rule of law has value because of the social consensus that it will be enforced. When a crime is committed, it is often because someone thinks they will get away with it. If everyone stops believing that the rule of law will be enforced, anarchy may break out, and society may cease to exist.
Similarly, centralized fiat currencies are able to be used at scale and over long periods due to the mutual information between market participants that the currency has value. It is in both of our interests that we believe the dollar has value, as that allows us to easily transact with each other (See also: network effects, common knowledge, social equilibrium, minimum viable superorganism).
The general principles of how to found a company are usually memetic-cooperative: it is good for us if we make it easy to found businesses and create new things, generally speaking.
Memetic-competitive
Much of the most useful information, however, is memetic-competitive: its value decrease the more people that find it. If you have ever thought of an idea that was so good that you were reluctant to share it with anyone, that’s a sign it was memetic-competitive.
An obvious example of a memetic-competitive idea is a market undervaluing an asset. If you have an easy way of making money by finding under-priced assets, this will stop working if you share it with enough people, as eventually the inefficiency will be fully exploited. You have a true idea that may literally cease to be true if you share it with enough people.
Those knowledgeable of the basics of game theory may find that some (but not all) cases of memetic-competitive ideas map onto defection. I could discover that if I cut to the front of the line, no one will stop me, and I can selfishly save myself time. If everyone implements this strategy, the entire queuing system will break. But even if they don’t, I am taking time away from them in order to give it to myself. Systems usually solve defection like this by making games iterated: if everyone in my town knows I’m the type of person to cut in line, the reputational hit may harm me enough to serve as deterrence (See also: iterated prisoner’s dilemma, free-rider problem, the virtue of silence).
Memetic-competitive information is a subset of anti-memetic information (information which ‘does not want’ to be shared). Another example of anti-memetic information is information which has little or negative value to a majority of agents in an ecosystem (if I posted a long random string on social media, it would probably not be picked up by any meme-promulgating algorithms and is thus anti-memetic).
Execution specifics of recently successful go-to-market strategies for consumer startups are often memetic-competitive. While it’s common to share generally good sales and advertising advice, it is uncommon for the specific tactics that startups tediously searched for and executed upon to be fully divulged to potential competitors (See also: things I wish more founders would understand about b2c marketing).
Social Media
Most social media (and the broader information economy) exists to propagate memetic information. As memetic-competitive information is anti-memetic (no one wants to spread it, lest it loses value), it follows that it is not something which will be easy to find on social media (See also: alpha used both in its original financial context, but also in non-financial contexts of finding strategies which give you an edge over competitors).
For an uncommon enough individual, it may be challenging to find the most useful information, because you first have to find a community of other individuals that value the same thing. Furthermore, if the information you are after is memetic-competitive, this can only exist in small communities, so you will have to hunt them out. Unfortunately it follows that it will be hard to hunt them out, because if the community has no barriers to entry and lets anyone join, then all the memetic-competitive information they share will quickly lose its value and the community will cease to exist. Luckily not all information is of the memetic-competitive type, although there’s still many other dynamics of virality to consider (See also: geeks, mops, and sociopaths in subculture evolution on the dynamics of community change over time as new actors with different incentives join, the melancholy of subculture society on internet subculture, and border stories: why is it that every unit of life from the cell to the immune system to the country to the planet all seem to have borders).
Further Complexity
Some information can move between different memetic information categories depending on its truth value. For example, take the sentence “AI is going to kill us”. If this sentence is true, then it is memetic-cooperative: we want everyone to know about it so that we can work together to stop it. If this sentence is false, however, it could be (partially) memetic-competitive: perhaps I want you to believe AI is dangerous so that I am able to profit from AI while you are not (I don’t think this is currently the case for most actors).
Things get complicated when we introduce the fact that not only do different agents have different values, but the perceived truth value of statements will also differ between agents (and especially) groups. If we wanted to we could also construct a model of memetics which is separate from the delta of informational value that propagation of the meme causes, if we wanted to get closer to fully modeling modern information exchange (See basic reproduction number R0, which is in my opinion the best way to model internet memes).
I’m going to stop the post here before this attempted formalism is over-extended, as my primary motivation is only to publicize the three labels I choose for future reference. My hope is that this post is memetic-cooperative!
few hit AI apps exist because LLMs are what i’d call very “strangely-shaped” tools.
most tools are built with a specific purpose in mind like a screwdriver or a car.
but LLMs were something we stumbled upon by predicting text and playing with RL – we didn’t design the shape of them beforehand, we just let them naturally evolve into what the loss optimized for.
it’s clear they’re good at many things, but they are so strangely shaped that it’s easy to fall into traps when making products.
AI agents are a good example of a trap (for now), where it’s easy to spend months trying to perfect your scaffolding yet never quite reaching the level of reliability you’d hope for.
long-term memory implemented solely via RAG is another trap. it’s just tempting enough to try, but the results aren’t as good as they should be.
other common inadequacies include poor search, hallucinations, and high inference costs. but there’s a long list of subtle weaknesses which few tinkerers ever notice as well as many weaknesses (and strengths) which remain unfound.
much of the frontier of LLM posttraining is currently concerned with these inadequacies – wondering how we can mold these strangely-shaped LLMs we have grown into a slightly more suitable form for the problems we face.
this is hard, even for the major labs. as we slowly progress on it, i’d expect to continue to see most AI products attempt to solve the same problems via the same methods, further suffering from lack of distinctness both in performance and aesthetic, because they don’t have the right connection between research teams and product teams (or perhaps the right vision to begin with).
it’s telling that among the few recent consumer successes like midjourney or perplexity, competitors are hyper-focused on directly copying winners rather than exploring the vast new frontier of things which could be built instead. this makes sense because the frontier is strangely-shaped, as a result of the underlying catalyst itself being strangely-shaped.
it’s not uncommon for services to launch a feature literally called “AI” which is primarily composed of literal magic wands and glitter emoji simply because the product designer has no idea how to actually convey the intended experience to the user. 2024 is certainly not a year one would be fired for using too much AI.
I expect it to get more interesting later this year and especially in 2025, but it’s still been a surreal experience continually contrasting my day to day life in san francisco with that of the actual real world (note: SF is not real in this example).
the above is also relevant to some of the reasons i have longer agi timelines than i did a few years ago. agi is not a strangely-shaped tool. in fact, it is quite literally the opposite.
If you liked this post you may be interested in the rest of my website too!
The bouba/kiki effect is the phenomenon where humans show a preference for certain mappings between shapes and their corresponding labels/sounds. Note: this post is from 2021, and likely seems much less novel whenever you’re currently reading it.
One of the above objects shall be called a bouba, and the other a kiki
The above image of 2 theoretical objects is shown to a participant who is then asked which one is called a ‘bouba’ and which is called a ‘kiki’. The results generally show a strong preference (often as high as 90%) for the sharply-pointed object on the left to be called a kiki, with the more rounded object on the right to be called a bouba. This effect is relatively universal (in languages that commonly use the phonemes in question), having been noted across many languages, cultures, countries, and age groups (including infants that have not yet learned language very well!), although is diminished in autistic individuals and seemingly absent in those who are congenitally blind.
What makes this effect particularly interesting is less so this specific example, but that it appears to be a general phenomenon referred to as sound symbolism: the idea that phonemes (the sounds that make up words) are sometimes inherently meaningful rather than having been arbitrarily selected. Although we can map the above two shapes to their ‘proper’ labels consistently, we can go much further than just that if desired.
Which is a takete, and which is a maluma? Only you can decide.
We could, of course, re-draw the shapes a bit differently as well as re-name them: the above image is a picture of a ‘maluma’ and a ‘takete’. If you conformed to the expectations in the first image of this section, it’s likely that you feel the maluma is the left shape in this image as well.
We can ask questions about these shapes that go far beyond their names too; which of these shapes is more likely to be calm, relaxing, positive, or explanatory? I would certainly think the bouba and maluma are all four of those, whereas the kiki and takete seem more sharp, quick, negative, or perhaps even violent. If I was told that the above two shapes were both edible, I can easily imagine the left shape tasting like sweet and fluffy bread or candy, while the right may taste much more acidic or spicy and possibly have a denser and rougher texture.
Sound symbolism
The idea that large sections of our languages have subtle mappings of phonemes to meaning has been explored extensively over time, from Plato, Locke, Leibniz, and modern academics, with different figures suggesting their theorized causes and generalizations.
Some of my favorite examples of sound symbolism are those found in Japanese mimetic words: the word jirojiro means to stare intently, kirakira to shine with a sparkle, dokidoki to be heart-poundingly nervous, fuwafuwa to be soft and fluffy, and subesube to be smooth like soft skin. These are some of my favorite words across any language due to how naturally they seem to match their definitions and how fun they are to use (more examples because I can’t resist: gorogoro may be thundering or represent a large object that begins to roll, potapota may be used for dripping water, and kurukuru may be used for something spinning, coiling, or constantly changing. There are over 1,000 words tagged as being mimetic to some extent on JapanDict!).
For fun I asked some of my friends with no prior knowledge of Japanese some questions about the above words, instructing them to pair them to their most-likely definitions, and their guesses were better than one would expect by random chance (although my sample size was certainly lacking for proper scientific rigor). The phonestheme page on Wikipedia tries to give us some English examples as well, such as noting that the English “gl-” occurs in a large number of words relating to light or vision, like “glitter”, “glisten”, “glow”, “gleam”, “glare”, “glint”, “glimmer”, “gloss”. It may also be worth thinking about why many of the rudest and most offensive words in English sound so sharp, often having very hard consonants in them, or why some categories of thinking/filler words (‘hmm’… ‘uhhh…’) sound so similar across different languages. There are some publications on styles of words that are found to be the most aesthetically elegant, including phrases such as ‘cellar door’, noted for sounding beautiful, but not having a beautiful meaning to go along with it.
Sound Symbolism in Machine Learning with CLIP
I would guess that many of the above aspects of sound symbolism are likely to be evident in the behavior some modern ML models as well. The reason for this is that many recent SOTA models often heavily utilize transformers, and when operating on text, use byte-pair encoding (original paper). The use of BPE allows the model to operate on textual input smaller than the size of a single word (CLIP has a BPE vocab size of 41,192), and thus build mappings of inputs and outputs between various subword units. Although these don’t correspond directly to phonemes (and of course, the model is given textual input rather than audio), it’s still likely that many interesting associations can be found here with a little exploration.
To try this out, we can use models such as CLIP+VQGAN or the more recent CLIP-guided diffusion, prompting them to generate an image of a ‘bouba’ or a ‘kiki’. One potential issue with this is that these words could have been directly learned in the training set, so we will also try some variants including making up our own. Below are the first four images of each object that resulted.
four images of “an image of a bouba | trending on artstation | unreal engine”
four images of “an image of a kiki | trending on artstation | unreal engine”
The above eight images were created with the prompt “an image of a bouba | trending on artstation | unreal engine”, and the equivalent prompt for a kiki. This method of prompting has become popular with CLIP-based image generation models, as you can add elements to your prompt such as “unreal engine” or “by Pablo Picasso” (and many, many others!) to steer the image style to a high-quality sample of your liking.
As we anticipated, the bouba-like images that we generated generally look very curved and elliptical, just like the phonemes that make up the word sound. I have to admit that the kiki images appear slightly less, well, kiki, than I had hoped, but nonetheless still look cool and seem to loosely resemble the word. A bit disappointed with this latter result, I decided to try the prompt with ‘the shape of a kikitakekikitakek’ instead, inserting a comically large amount of sharp phonemes all into a single made-up word, and the result couldn’t have been better:
the shape of a kikitakekikitakeki | trending on artstation | unreal engine
Having inserted all of the sharpest-sounding phonemes I could into a single made-up word and getting an image back that looks so amazingly sharp that it could slice me in half was probably the best output I could have hoped for (perhaps I got a lucky seed, but I just used 0 in this case). We can similarly change the prompt to add “The shape of” for our previous words, resulting in the shape of a bouba, maluma, kiki, and takete:
the shape of a bouba (top left), maluma (top right), kiki (bottom left), and takete (bottom right)
It’s cool to see that the phoneme-like associations within recent large models such as CLIP seem to align with our expectations, and it’s an interesting case study that helps us imagine all of the detail that is embedded within our own languages and reality – there’s a lot more to a word than just a single data point. There’s *a lot* of potential for additional exploration in this area and I’m definitely going to be having a lot of fun going through some similar categories of prompts over the next few days, hopefully finding something interesting enough to post again. If you find this topic interesting, some words you may want to search for along with their corresponding Wikipedia pages include: sound symbolism, phonestheme, phonaesthetics, synesthesia, ideathesia, and ideophone, although I’m not currently aware of other work that explores these with respect to machine learning/AI yet.
Thanks for reading! I appreciate feedback via any medium including email/Twitter, for more information and contact see my about page
This Anime Does Not Exist was launched on January 19th 2021, showcasing almost a million images (n=900,000 at launch, now n=1,800,000 images), every single one of which was generated by Aydao‘s Stylegan2 model. For an in-depth write-up on the progression of the field of anime art generation as well as techniques, datasets, past attempts, and the machine learning details of the model used, please read Gwern’s post. This post is a more concise and visual post discussing the website itself, thisanimedoesnotexist.ai, including more images, videos, and statistics.
The Creativity Slider and Creativity Montage
Previous versions of ‘This X Does Not Exist’ (including anime faces, furry faces, and much more) featured a similar layout: an ‘infinite’ sliding grid of randomly-selected samples using the javascript library TXDNE.js, written by Obormot. Something more unique about Aydao’s model was that samples remained relatively stable, sometimes significantly increasing in beauty and detail as the ‘creativity’ value (see: psi) was increased all the way from 0.3 to 2.0. This led to the creation of the ‘creativity slider’ as well as linking every image to a page with a tiled layout showing every version of the image:
“The more entropy you give me, the more it makes me want to smile!”, 18 samples of image # X from creativity 0.3 to 2.0
One of the best and most common effects of higher creativity is better colorization, including shading, reflections, vibrancy, color diversity, and more
Another tile of seed 7087, showcasing stability with an increasingly interesting artistic style and details
Although the above two are among my favorite examples of creativity montages, many users found some other interesting things that increased creativity could do:
Sometimes it appeared as if ‘creativity’ was simply an alias for the increase in volume of a certain bodily area coupled with a proportional reduction of garment-covering surface area (seed 30700)
Sometimes increased creativity also leads to mitosis (seed 28499)
Sometimes you get… a lot of mitosis?
Selected artwork
The best way to demonstrate the stunning potential of this model is to show some of the samples that users have enjoyed the most:
The original thumbnail image for This Anime Does Not Exist: “Notice me, Onee-chan!”
Other earlier candidates considered for the website’s thumbnail (seeds: 1013, 4606, 8674, 8859)
Incidentally, it also seems that users love sharing images that are not the most beautiful, but the weirdest as well. The below four were among the most popular images on the website during the first few hours, when there was only n=10,000 of each image:
A montage of the interesting and popular results from images 3313, 7820, 4437, and 3103. Sample 3103 would be a particularly good album cover for a death metal band.
Collapsed images
Sometimes the result collapses enough to lead to an image that, although pretty, does not at all resemble the ideal target:
interesting but unintended results from samples 0544, 31975, 3997, 0557
Writing
In many cases the model will produce writing which looks distinctly Japanese, however upon closer introspection, is not legible, with each character closely resembling distinct counterparts in Japnese scripts, however diverging just enough to produce confusion with a lingering feeling of otherworldlyness.
Although some characters are easily recognizable, many are not, and are nonetheless *usually* combined in incoherent manners
Videos and gifs
As it’s possible to produce any number of images from the model, we can also use these images to produce videos and animated gifs. The primary style of this is referred to as an interpolation video which is produced by iterating through the latent variables frame by frame, transitioning in between different samples seamlessly:
Additionally, I decided to make a few videos that used a constant image seed, but modified only the creativity value instead (instructions on how I did this are here):
I chose this particularly wholesome sample to demonstrate a gif with creativity 0.3-2.0 and a frame difference of 0.01
Statistics and users
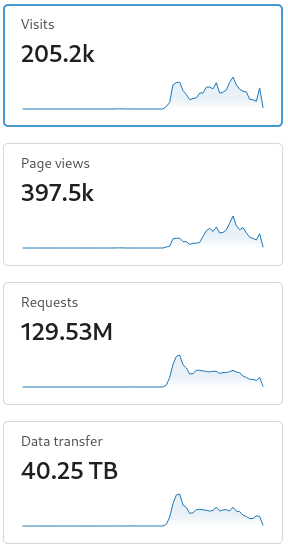
After the first day, the website had served over 100 million requests, using over 40TB of bandwidth:
First-day traffic statistics from CloudFlare’s Traffic Analytics
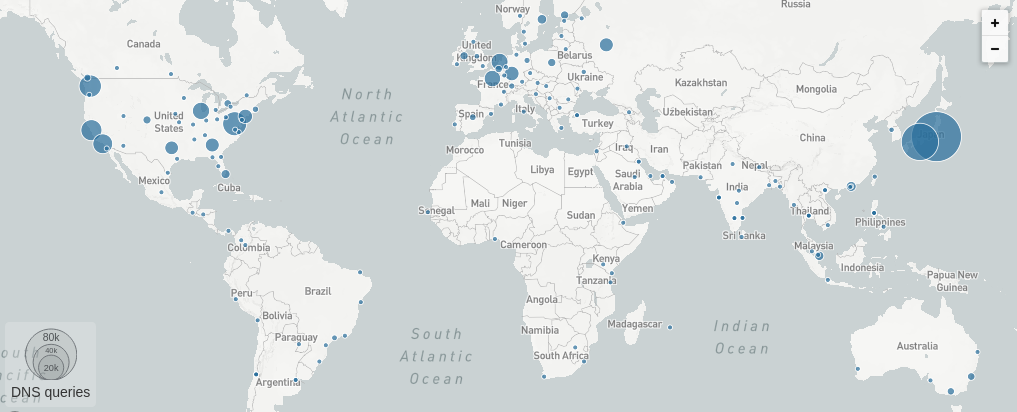
At launch, the largest contributor to traffic by country was the United States, followed by Russia, but over the next two days this quickly shifted to Japan.
A map showing which of Cloudflare’s data centers served the most DNS query results for the domain
Compare to similarly-trafficed websites, thisanimedoesnotexist.ai was relatively cheap, thanks to not requiring server-side code (serving only static content):
Domain ‘thisanimedoesnotexist.ai’: for two years from NameCheap: $110
Cloudflare premium, although not required, improves image load time significantly via caching with their global CDN: $20
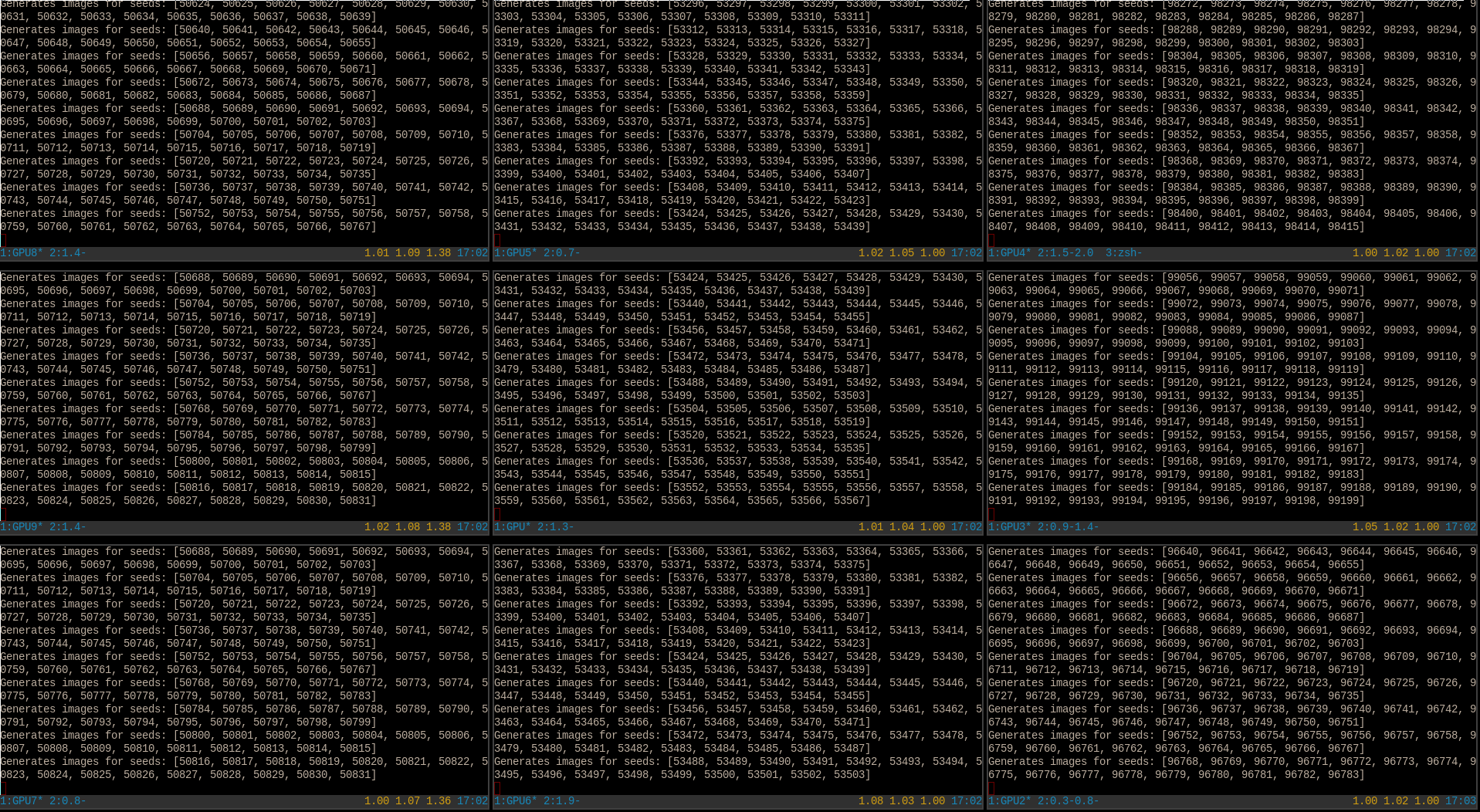
Image generation: 1,800,000 images, 10,000 generated per hour with a batch size of 16 using a g4dn.xlarge instance, which has a single V100 GPU with 16GB of VRAM at $0.526 per hour on-demand: $95
“Accidentally” hosting the website from AWS for the first day, resulting in over 10TB of non-cached bandwidth charges: >$1,000 (via credits)
An image of what my desktop looks like while generating an additional million anime imagesWhat the access log for nginx looks like while serving >1,000 anime images per second
Yet another example of why to not use AWS for high-bandwidth content: AWS has some of the most expensive bandwidth at $0.09 per GB (luckily this was paid for entirely with credits and the migration off of AWS was complete in less than a day to a more sustainable provider)
Conclusions and the future
All in all, this was a fun project to put together and host, and I’m glad that hundreds of thousands of people have visited it, discussed it, and enjoyed this novel style of artwork.
If you want to read in-depth about the ML behind this model and everything related to it, please read Gwern’s post.
Thank you to Aydao for relentlessly improving Stylegan2 and training on danbooru2019 until these results were achieved as well as releasing the model for anyone to use, Obormot for the base javascript library used, TXDNE.js, Gwern for producing high-quality writeups, releasing the danbooru datasets, and and other members of Tensorfork including Gwern, arfa, shawwn, Skyli0n, Cory li, and more.
The field of AI artwork, content generation, and anything related is moving very quickly and I expect these results to be surpassed before the year is over, possibly even within a few months.
If you have a technical background and are looking for an area to specialize in, I cannot emphasize the extent that I’d strongly suggest machine learning/artificial intelligence: it will have the largest impact, it will affect the most fields, it will help the most people, it will pay the most, and it will cause you to be surrounded by the best and smartest people you could hope for.
Thanks for reading and I hope you enjoyed the website! For more about myself, feel free to read my about page or see my Twitter.