few hit AI apps exist because LLMs are what i’d call very “strangely-shaped” tools.
most tools are built with a specific purpose in mind like a screwdriver or a car.
but LLMs were something we stumbled upon by predicting text and playing with RL – we didn’t design the shape of them beforehand, we just let them naturally evolve into what the loss optimized for.
it’s clear they’re good at many things, but they are so strangely shaped that it’s easy to fall into traps when making products.
AI agents are a good example of a trap (for now), where it’s easy to spend months trying to perfect your scaffolding yet never quite reaching the level of reliability you’d hope for.
long-term memory implemented solely via RAG is another trap. it’s just tempting enough to try, but the results aren’t as good as they should be.
other common inadequacies include poor search, hallucinations, and high inference costs. but there’s a long list of subtle weaknesses which few tinkerers ever notice as well as many weaknesses (and strengths) which remain unfound.
much of the frontier of LLM posttraining is currently concerned with these inadequacies – wondering how we can mold these strangely-shaped LLMs we have grown into a slightly more suitable form for the problems we face.
this is hard, even for the major labs. as we slowly progress on it, i’d expect to continue to see most AI products attempt to solve the same problems via the same methods, further suffering from lack of distinctness both in performance and aesthetic, because they don’t have the right connection between research teams and product teams (or perhaps the right vision to begin with).
it’s telling that among the few recent consumer successes like midjourney or perplexity, competitors are hyper-focused on directly copying winners rather than exploring the vast new frontier of things which could be built instead. this makes sense because the frontier is strangely-shaped, as a result of the underlying catalyst itself being strangely-shaped.
it’s not uncommon for services to launch a feature literally called “AI” which is primarily composed of literal magic wands and glitter emoji simply because the product designer has no idea how to actually convey the intended experience to the user. 2024 is certainly not a year one would be fired for using too much AI.
I expect it to get more interesting later this year and especially in 2025, but it’s still been a surreal experience continually contrasting my day to day life in san francisco with that of the actual real world (note: SF is not real in this example).
the above is also relevant to some of the reasons i have longer agi timelines than i did a few years ago. agi is not a strangely-shaped tool. in fact, it is quite literally the opposite.
If you liked this post you may be interested in the rest of my website too!
This post was made in 2019. By 2026+ its suggestions are likely mostly invalid due to AI
Google’s ReCAPTCHA is often the first tool that many webmasters reach for when confronted with the need to stop spam and automated malicious traffic from harming their services. In this post I explain several reasons why ReCAPTCHA is usually not the best solution to use for this purpose, as it is often unnecessary, inconveniences users, and subjects users to intensive tracking and fingerprinting that they are not able to opt-out of. Several alternative solutions to ReCAPTCHA for various threat models are presented as well as best practices for implementing captchas in general.
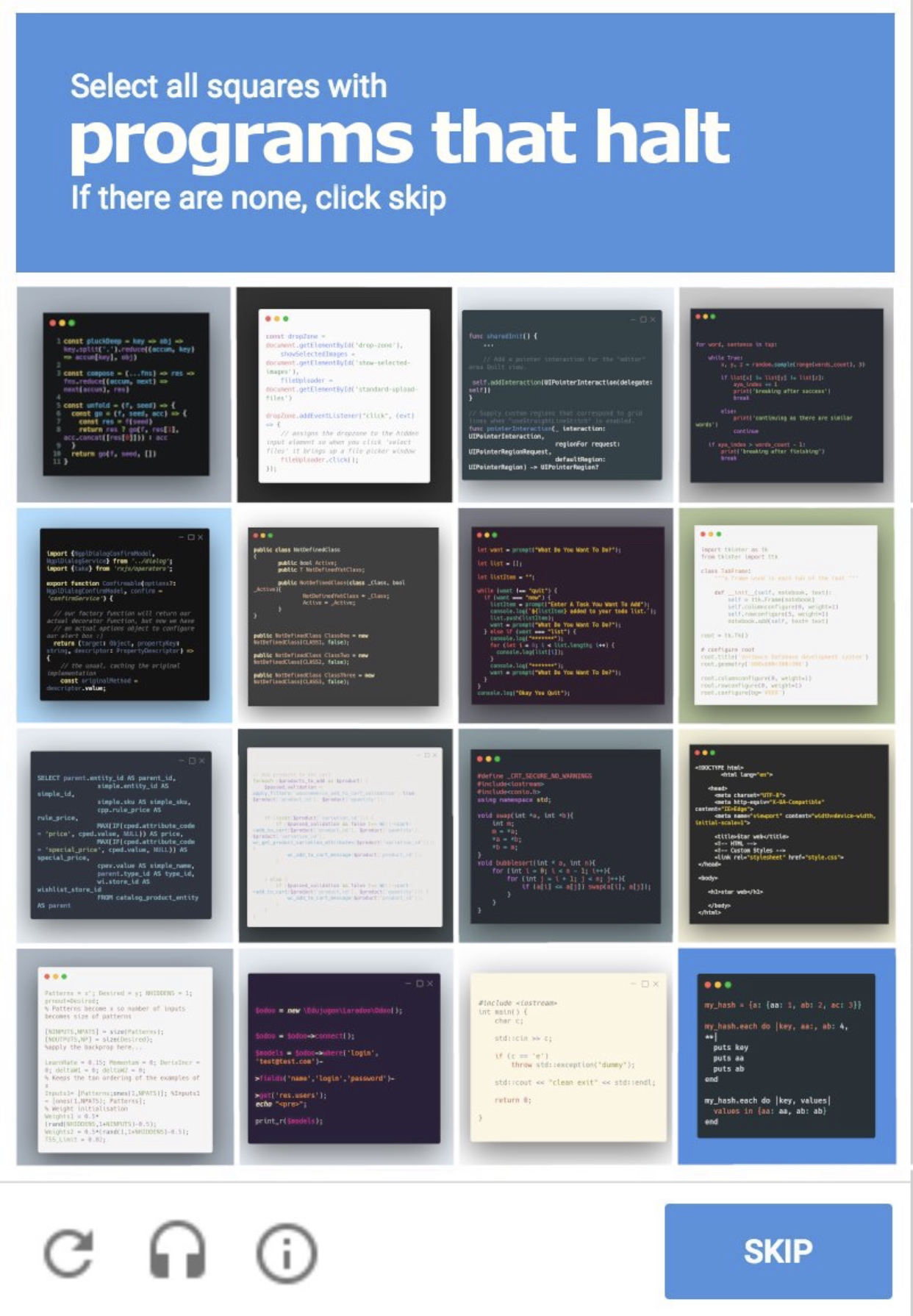
The face of evil
ReCAPTCHA is harmful
ReCAPTCHA is yet another free-of-charge product offered benevolently by Google for any webmaster to implement within their own services. How does ReCAPTCHA differentiate legitimate human users from bots? ReCAPTCHA relies extensively on user fingerprinting, putting emphasis on the question of “Which human is this user?” rather than the ordinary “Is this user human?”. It’s worth noting how much easier it is to successfully solve ReCAPTCHAs when the user is logged into their Google account, thus allowing Google to associate their actions with their real identity. A similar effect is often reported for users of non-Google browsers, who notice ReCAPTCHAs take more time to complete in Firefox over Chrome. This is in-line with many other anti-competitive techniques that Google has used over the years to help grow their market share.
Although determining
exactly how ReCAPTCHA works is very difficult, with Google not only
heavily obfuscating its JavaScript, but also implementing an entire
VM in JavaScript with its own bytecode language, there have still
been many attempts to reverse-engineer some of the client-side code,
as well as to theorize about how the server-side logic operates.
Initial attempts
at reverse-engineering ReCAPTCHA show copious amounts of information
belong collected, including but not limited to: plugins, user agent,
IP address, screen resolution, execution times, timezone, language,
click/keyboard/touch information within the frame of the captcha,
test results of many browser-specific functions and CSS evaluation,
information about canvas element rendering, and cookies, including
those affiliated with your Google account that were placed within the
last 6 months.
There is a good reason why ReCAPTCHA uses the google.com domain instead of one specific to ReCAPTCHA. This allows Google to receive any cookies that they have already set for you, effectively bypassing restrictions on setting third party cookies and allowing traffic correlation with all of Google’s other services, which most users use. ReCAPTCHA collects enough information that it could reliably de-anonymize many users that simply wish to prove that they are Not A Robot. As JavaScript is now required to even view a ReCAPTCHA, even a user running software such as TBB (Tor Browser Bundle) may find themselves giving away more information than they intend to, for example if they have resized their browser window (which is discouraged for exactly this reason).
Some unlucky ReCAPTCHA questions seem down right impossible for some users
Correspondingly, webmasters that use Google’s ReCAPTCHA on their websites must link to both Google’s Privacy and Terms pages (included in the form by default in a small 8px style that makes them appear unclickable). Although Google used to have its own privacy and terms pages for ReCAPTCHA, these links are no longer specific to ReCAPTCHA, but rather are the privacy and terms pages for all users of Google services in general, regardless of which service is being used, or if the user has (or even wants) a Google account to begin with. Therefore accepting these terms (implicitly, by attempting to prove you are Not A Robot) grants Google permission to do everything that they do to their regular users of their services to you, and little information is available as to what specifically is done (GDPR is likely to be unhelpful here, given ReCAPTCHA’s spam-stopping purpose). Not only are the unhelpful links in the ReCAPTCHA box never opened by users, but there is also no Google logo or visual reference to indicate that ReCAPTCHA is a Google service, so many users have zero indication that they have just consented to all of Google’s tracking just because they tried to leave feedback or create a ticket on your website. If you thought you could use the Internet without using Google’s services, try using the Internet without filling out a single ReCAPTCHA, which for some users is required to pay their bills, file their taxes, and sometimes even use Government websites (if you somehow manage this, next try never sending email to Gmail/Gsuite addresses or using Google APIs for a more exciting challenge). Good luck.
It is worth mentioning that caring about user privacy to this extent is likely to be outside of the scope of concern for most websites. Many websites are already so tightly coupled to Google’s services (commonly including Google analytics, Google ads, Google APIs, Google tag manager, Google static resources, Google OAuth, Google Compute Engine, and many others) that the addition of a Google captcha appears negligible. With that said, different websites have different values and different users, and many do not want to require users to agree to Google’s tracking and labor for basic usage. The level of centralization that ReCAPTCHA forces is not good for anyone except Google.
Apart from the privacy implications of ReCAPTCHA usage, the actual captcha is very tedious for many classes of users, sometimes becoming so difficult that users find themselves unable to to complete the captcha at all. Users hate ReCAPTCHA. TheyreallyhateReCAPTCHA. ReCAPTCHAissohated that some websites have a profit model of charging users $20 annually to disable ReCAPTCHA, which thousands of users pay for. If this sounds like a great new business model to you and now you want to add ReCAPTCHAs to every page of your website to attempt to maximize profit, I will find you. And I will force you to complete a ReCAPTCHA every time you want food or water until you die from malnutrition after the first week. I have read countless posts from users that became so frustrated with a service that used excessive ReCAPTCHAs that they swore to never use the offending website again. These are often intelligent users with no disabilities who are simply tired of being treated like dirt and wasting their time. Be kind to your users and help minimize the amount of ReCAPTCHAS that they have to solve just to be allowed to use the Internet.
ReCAPTCHAs become significantly more difficult if the user attempts to ‘opt-out’ of Google’s services and tracking by using software that hinders it, such as VPNs, TBB, and many anti-tracking browser addons and modifications. To demonstrate what is meant by ‘very tedious’, below is a real-time recording of myself solving a single ReCAPTCHA using TBB:
Spambots are known to give up when forced to be patient
I got lucky and only needed to complete two challenges. Sometimes there are ten or more. Watching the above video, you might think to yourself “I knew the tor network was slow, but I didn’t know it was that slow!”. You would be correct to take note of this discrepancy. If we open up the web developer console, we can see that the HTTP requests for new captcha images only take a few hundred milliseconds. Despite this, Google’s heavily-obfuscated JavaScript intentionally delays the appearance of the new images by several seconds every time, which I’m sure has something to do with the fact that bots give up when forced to wait, probably. This is not a nice way to treat users that don’t want to perform unpaid labor and be fingerprinted by Google. Keep in mind that the above video demonstrates one of the worst possible cases of ReCAPTCHA UX (which some userscripts may improve), and that the average user has a significantly quicker experience, providing that they are not attempting to thwart any of Google’s tracking and don’t make many mistakes.
In addition to this tediousness, the actual labor that the user is performing is directly used to benefit Google. Worry not however, as Google is eager to brag about the selfless humanitarianism that you’re engaging in by choosing ReCAPTCHA, stating the following on their main ReCAPTCHA page:
“Hundreds of millions of captchas are solved by people every day. ReCAPTCHA makes positive use of this human effort by channeling the time spent solving captchas into digitizing text, annotating images, building machine learning datasets.”
This
is certainly a very rosy way of convincing
you to feel good about forcing
your users to engage in unpaid labor that directly benefits the
world’s most powerful surveillance corporation. ReCAPTCHA
is free for a reason.
Lastly, ReCAPTCHA is popular. Very popular. While this brings some advantages, it also means that there’s significant efforts to break ReCAPTCHA, and those efforts all potentially affect your website, with your captcha implementation being perfectly identical to a million others. As a result of this, there have been manypaperspublishedthatbreakReCAPTCHA over the years, generally with Google making modifications to improve their captcha afterwards. There have also been paid-forservices that use human labor to solve captchas on behalf of a paying client for less than a cent each. For a modern and user-friendly example of bypassing ReCAPTCHA, see Buster. Buster is a modern browser extension (Firefox+Chrome+Opera) which helps you to solve difficult captchas by completing reCAPTCHA audio challenges for you by using speech recognition.
Captchas are not always necessary
Before implementing a captcha, it’s worth considering if one is
necessary to begin with. To help with evaluating this proposition,
consider if your threat model is concerned over customized or
uncustomized spam. Uncustomized spam is pervasive across many
Internet protocols, and you will encounter it quickly after enabling
HTTP, SSH, or many other protocols on a server. It is generally
unintelligent, cheap to execute, and easy to block, even without
captchas. Customized spam, however, is spam that has been written to
specifically affect a given company, service, website, or user. As
customized spam is created by an actor that is able to tailor it to
your service, it is more dangerous than uncustomized spam, and more
effort is required to effectively limit it.
Many developers vastly over-estimate the likelihood
of customized spam. As a
competent programmer, it is easy to imagine how effortlessly
someone could decimate your service with spam if they were
sufficiently dedicated. One
could imagine a malicious actor writing a simple script that could
spam or DoS your website by just using Curl and bash. Even if you
have a captcha, you can imagine them using OCR or machine learning to
automatically bypass it, then
using proxies and VPNs to automatically bypass
your IP rate-limiting. While
in this imaginative trance, you’ve forgotten that 99% of users have
no clue how to do any of this, and
do not even know what Curl or HTTP are.
Furthermore, your service
likely offers
very little prospective rewards to would-be competent attackers.
Just because someone could
spend hours (or
minutes) writing
a program to spam your website does not mean
that
someone
will.
Your
personal blog about the latest vegan bacon is not a high-priority
target for anyone. Adding a
ReCAPTCHA to your Contact Me page is just
a great way to get
no one to talk to you. I’ve
ran several websites with millions of pageviews that have received
zero customized abuse and have spoken to other webmasters with
similar experiences. Jeff
Atwood of codinghorror.com
once wrote
similarly:
The comment form of my blog is protected by what I refer to as “naive captcha”, where the captcha term is the same every single time. This has to be the most ineffective captcha of all time, and yet it stops 99.9% of comment spam.
This is not a suggestion to do nothing, ignore basic security, and be unprepared for attacks, but rather to realistically consider your threat model and apply only what is necessary.
ReCAPTCHA
alternatives for uncustomized spam
For uncustomized spam, a full
captcha implementation is
rarely necessary. This section lists some simple and
effective tricks that stop most uncustomized spam from impacting
your website.
Hidden form elements
Uncustomized spam is not intelligent enough to know when it should
or should not fill out a form element. For example, adding a form
element with a name of ‘url’ and hiding it with CSS allows you to
reject any request that is made with it filled, which spambots are
eager to do. To maintain accessibility be sure to add a label to this
element so that users who use screen readers do not fill it out.
Other good hidden form element names include ‘website’,
‘firstname’, ‘lastname’, ‘email’, and ‘name’, unless
they are already being used legitimately.
Static questions
Uncustomized spambots are also so unintelligent that they do not correctly answer simple questions such as “What is 2+3?”, or “what is the name of this website?”. These questions effectively stop almost all uncustomized spam. Common software stacks such as WordPress and Drupal have freeplugins that will allow you to quickly create questions like these.
Community-specific questions
If your website is community-centric such as a forum or blog, you
can ask a community-specific question that prospective members of
your community should know the answer to. This is a simple and great
way to prevent users from joining your community that you believe
shouldn’t be participating, either because they lack basic relevant
knowledge, or because they are unable or unwilling to learn it. As an
example, a community of mathematicians might ask the user to name a
simple formula or solve an equation, given an image of it.
Effective at keeping out the arithmophobic
For
another example, a community of niche media connoisseurs might ask
the user to identify a certain character that they deem to be
important to their shared culture.
The quality of our community members is of the utmost importance
JavaScript
Did I mention uncustomized spambots are unintelligent? Basic JavaScript is not executed or parsed by most uncustomized spambots, so using it to calculate the value of a form element is also effective. JavaScript can also be used to submit the form itself, set a CSRF token properly, or perform many other simple tasks. If your site has many users with JavaScript disabled, it is better to offer an alternative solution as well.
Third Party Services
From WordPress plugins like Akismet, spam-detection APIs like StopForumSpam, and APIs that evaluate users or IPs such as abuseIPDB, there are a lot of free (and paid) third party services to aid you in stopping spam in ways that are not visible to most of your users.
ReCAPTCHA
alternatives for customized spam
If you operate at sufficient scale and/or if automated usage of your website is inherently lucrative enough, customized abuse will eventually happen for one reason or another. Remember that a captcha is just a tool to help verify that a given user is a human. It is not the only tool to help with this, and it is not the right tool for every use case. No solution is perfect and can stop a sufficiently-resourced attacker from abusing your service. This section lists some alternatives to ReCAPTCHA in roughly increasing order of complexity.
Popular CMS
solutions generally have at least one simple captcha plugin that is
suitable for basic purposes. Here are some examples for WordPress,
Drupal,
and generic PHP.
Secureimage PHP captcha
Drupal match+slide captcha
Custom JavaScript functionality
Just as basic
JavaScript stops
most uncustomized spam, more
advanced scripting
can stop a lot of customized spam as well. For example, some websites
require you to slide a jQuery
slider element in order to successfully submit
a form. There are examples of
this for wordpress,
jQuery
(jQuery
UI slider, Bootstrap
slider),
Prestashop,
Node,
and more, although
these examples may not be suitable for production use
and I have not tested them.
Slide to unlock
Just
including
true JavaScript evaluation as
a requirement will raise the
bar for attackers, and can be done without the user having to perform
any actions. If you choose to
write a lot of custom front-end code to evaluate users, be sure to do
extensive user testing on every type of device and log failures so
that they can be analyzed to further remove false positives.
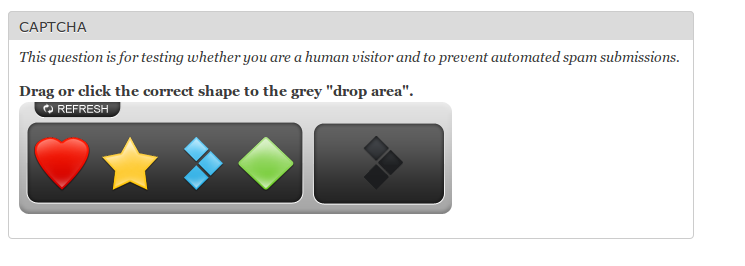
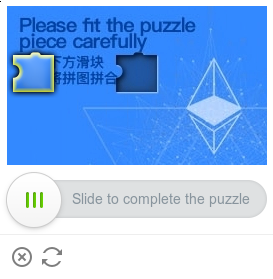
Capy Puzzle CAPTCHA
Capy offers a simple puzzle captcha that requires the user to drag a puzzle piece into an empty slot.
All of the fun of finishing a jigsaw puzzle with none of the effort
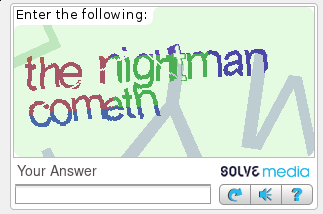
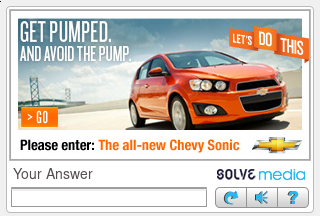
SolveMedia
SolveMedia
offers a captcha and corresponding plugins for a variety of popular
software stacks, including vBulletin, WordPress, MediaWiki, Dupal,
Joomla, and more. The captcha can scale its difficulty based on the
threat score of a user.
he’ll come when you least expect it
If for some reason you feel the need to profit off of your captcha implementation, fear not, as there’s also a version fit for the capitalistdystopia of the near future:
Please drink verification can
Geetest
Geetest appears to use some fingerprinting, but otherwise works similarly to most puzzle captchas. Notable for being used on Binance, one of the world’s largest cryptocurrency exchanges.
hCaptcha
Lastly, as of 2020, even Cloudflare has switched away from ReCAPTCHA, instead using hCaptcha, an alternative that seems just as difficult to bypass as ReCAPTCHA, but that respects user privacy, and potentially even pays some clients for their users’ labor in data labeling.
hCaptcha’s website, showing example captcha challenges
This list is nowhere near exhaustive and many similar captchas have been excluded from it. If you are a software engineer, you likely think many of these captchas could be solved by software, which although correct, misses the point. Although in theory a captcha should be a perfect turing test, in practice, they are only used to make attacking your service more difficult so that spam is no longer cost-effective. Even a perfect captcha provides no guarantee of stopping all abuse. Nonetheless, you may be surprised at how few attackers are willing to execute JavaScript or perform OCR to automatically attack your website unless you run an extremely popular service.
Captcha best practices
If you have decided that you do
need a captcha, consider if
it’s truly necessary to implement it in all of the locations where
you want to throttle automation. Showing
users fewer captchas not only
provides
a better UX, but also improves KPIs
like conversions and user
retention.
Use
rate-limiting where possible
As the purpose of a captcha is to confirm that the end-user is a
human, a user should generally only have to correctly solve a captcha
once. If there is an action that you would like to throttle to ensure
it is not performed too often by a user, consider using rate-limiting
as an alternative (or in combination with) a captcha.
Use reasonable thresholds for captcha
presentation
Set reasonable thresholds for actions that you want to limit with captchas. Rather than presenting a user with a captcha after a single failed login attempt, allow several attempts. Brute-forcing secure passwords in this manner is not feasible to begin with, and if credentials from a database leak are being automatically cross-validated with your service, a post-login-failure captcha won’t even help.
Stop showing captchas to users that are just trying to read content. If your blog asks me to complete a captcha just to read a single post because I’m using a super-scary VPN as a result of your CDN’s “premium military-grade bot protection” feature, I’m going to close the tab. There are sometimes cases where captchas are more reasonable for read-only actions such as stopping active application-level DDoS attacks. Your blog is not one of these cases.
Do not require repeated captcha solves
If a captcha is part of a form that may fail validation and is reloaded upon failure, do not force the user to solve another captcha if they correctly solved the first one. This prevents users having to frustratingly solve captchas several times in a row as they fix their input (for example, adhering to your revolutionary password policy that requires at least 1 non-printable character, 1 Egyptian hieroglyph, and 1 iOS-only emoji).
Intelligently use other sources of validation
Consider if you have reasonably validated that a user is likely to be a human during previous interactions with them. If a user has a confirmed email address and phone number or proper two-factor factor authentication, it may be unnecessary to show them a captcha. Similarly, if a user has been a paying customer for several months without issues and is attempting to make a new purchase with their existing billing information, it is also a bad time to make them fill out a captcha. I mention this only because I’ve had to do it before.
The future of verification
It’s important to note that a sufficiently-resourced attacker
can bypass any mechanisms you have in place to
some extent. When a service has a billion users (Facebook and
Twitter) or otherwise provides significant incentives for abuse
(anything related to cryptocurrency), difficult trade-offs must be
made when attempting to verify users.
Faced with this, some services that operate at very large scales not only use ReCAPTCHA, but also perform phone and/or email verification and employ a significant amount of custom automation-detecting heuristics. Twitter is a good example of this, as new users are required to both complete a ReCAPTCHA and (usually) verify a phone number. On top of this, Twitter has entire teams dedicating to stopping abuse, and yet the platform still has issues with millions of spambots, just as Facebook does. Although requiring phone verification has unfortunate consequences for anonymity, most platforms were not intended to be used anonymously to begin with. An even greater challenge is attempting to stop spam in environments where user anonymity is desired, which I provide some examples of at the end of this section.
With the current state of machine learning, it is becoming
increasingly difficult to construct a captcha that is user-friendly.
Some of the most effective
attacks on advanced captchas such as ReCAPTCHA have simply involved
taking a given challenge and querying a machine learning API to solve
it automatically. Now that we have manyAPIservices
to accurately label audio, images, videos, and more, this is only
becoming more powerful, just as machine learning is in general.
Despite the impossibility of a perfect captcha, articles have been written decrying that captchas are dead for more than a decade due to the increasing possibility of true negatives (software that passes as a human). Despite this, most of the Internet is not covered in spam. Intelligent software engineers make much more money working at FAANG instead of covering the Internet in unsolicited fake Viagra ads, at least for now. For a potentially poor analogy to physical security, remember that we have physical items that can break doors, windows, cameras, sensors, locks, and much more. Yet, these protections are all still essential features of a physical security system. They are often not made to be impossible to break, but rather to make an attacker’s job significantly more difficult, skewing the effort/reward ratio enough to stop most attackers.
Regardless of the forthcoming AI supremacy, the current paths that larger systems tend to favor involve validating who a specific user is rather than only attempting to validate if they are human or not. Phone verification and sometimes even picture, ID, or address verification are found among large services that have a high potential for abuse, as well as our good friend ReCAPTCHA. Verifying users while attempting to better preserve anonymity is more difficult, but those that are determined generally find clever ways to do so. Some good examples include privacy pass (protocol paper), allowing users to anonymously skip captchas if they have already solved one, Apple’s new Find My Device feature, allowing Apple devices to broadcast their location with BLE such that it can only be read by the original device’s owner, and well-known security systems such as asymmetric cryptography, cryptographic hashes, differential privacy, etc, which can often be cleverly implemented in systems to improve security and often anonymity. Some other techniques that can be used to help verify users and reduce spam include proof-of-work and micropayments, both of which have been used successfully in most popular cryptocurrencies such as Bitcoin and Ethereum for more than a decade, although can still be difficult to implement in everyday scenarios.
If you are Twitter or Facebook, no captcha will solve all of your issues. For everyone else, there are still a lot of simple tools and heuristics that go a long way in helping to stop abuse. Be kind to your users and try your best to not force them to spend their free time completing ReCAPTCHAs for Google. They will appreciate it.
If you enjoyed this post or have corrections feel free to say hi on Twitter








{kind=link}
{kind=link}